 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Lottery Ticket Hypothesis at Scale
Paper and Code
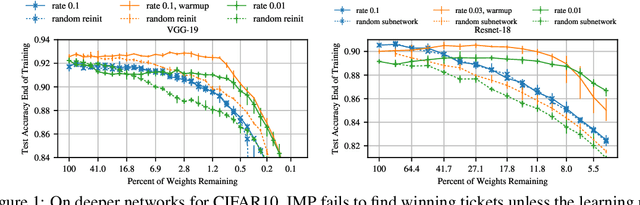
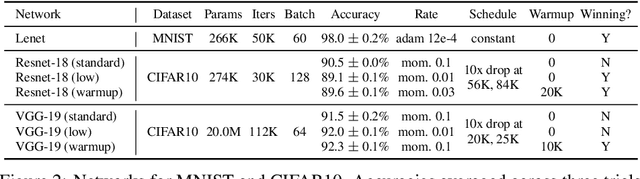
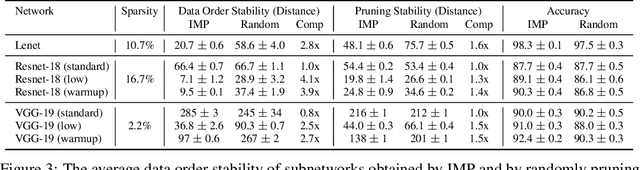
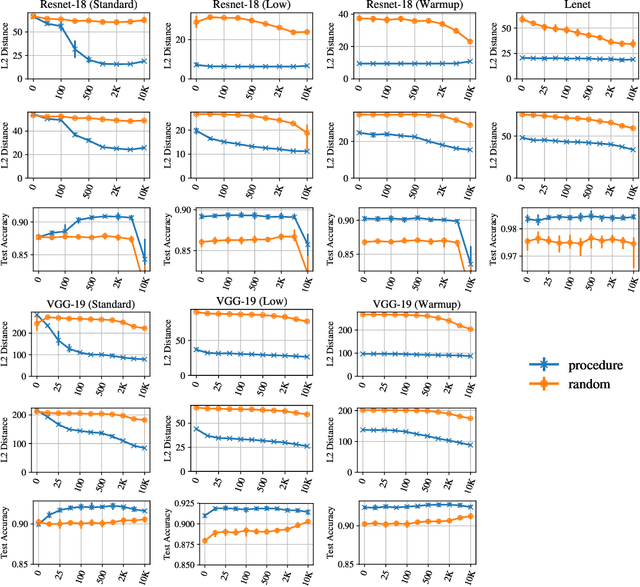
Recent work on the "lottery ticket hypothesis" proposes that randomly-initialized, dense neural networks contain much smaller, fortuitously initialized subnetworks ("winning tickets") capable of training to similar accuracy as the original network at a similar speed. While strong evidence exists for the hypothesis across many settings, it has not yet been evaluated on large, state-of-the-art networks and there is even evidence against the hypothesis on deeper networks. We modify the lottery ticket pruning procedure to make it possible to identify winning tickets on deeper networks. Rather than set the weights of a winning ticket to their original initializations, we set them to the weights obtained after a small number of training iterations ("late resetting"). Using late resetting, we identify the first winning tickets for Resnet-50 on Imagenet To understand the efficacy of late resetting, we study the "stability" of neural network training to pruning, which we define as the consistency of the optimization trajectories followed by a winning ticket when it is trained in isolation and as part of the larger network. We find that later resetting produces stabler winning tickets and that improved stability correlates with higher winning ticket accuracy. This analysis offers new insights into the lottery ticket hypothesis and the dynamics of neural network learning.