 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Gradient-Free Proximal Stochastic Methods for Nonconvex Nonsmooth Optimization
Paper and Code
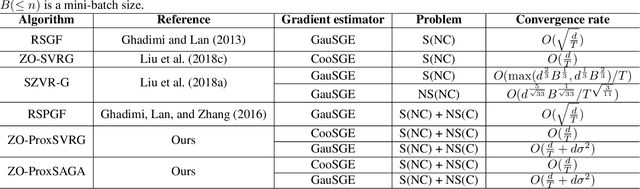
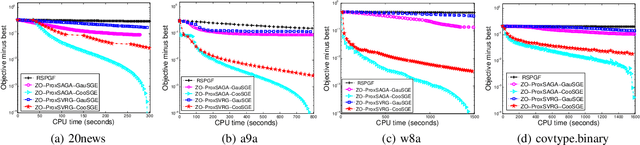

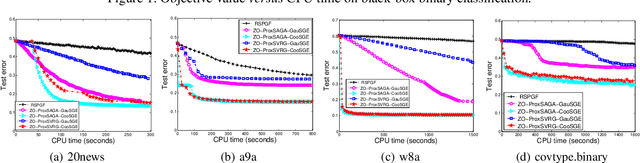
Proximal gradient method has been playing an important role to solve many machine learning tasks, especially for the nonsmooth problems. However, in some machine learning problems such as the bandit model and the black-box learning problem, proximal gradient method could fail because the explicit gradients of these problems are difficult or infeasible to obtain. The gradient-free (zeroth-order) method can address these problems because only the objective function values are required in the optimization. Recently, the first zeroth-order proximal stochastic algorithm was proposed to solve the nonconvex nonsmooth problems. However, its convergence rate is $O(\frac{1}{\sqrt{T}})$ for the nonconvex problems, which is significantly slower than the best convergence rate $O(\frac{1}{T})$ of the zeroth-order stochastic algorithm, where $T$ is the iteration number. To fill this gap, in the paper, we propose a class of faster zeroth-order proximal stochastic methods with the variance reduction techniques of SVRG and SAGA, which are denoted as ZO-ProxSVRG and ZO-ProxSAGA, respectively. In theoretical analysis, we address the main challenge that an unbiased estimate of the true gradient does not hold in the zeroth-order case, which was required in previous theoretical analysis of both SVRG and SAGA. Moreover, we prove that both ZO-ProxSVRG and ZO-ProxSAGA algorithms have $O(\frac{1}{T})$ convergence rates. Finally, the experimental results verify that our algorithms have a faster convergence rate than the existing zeroth-order proximal stochastic algorithm.