 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Temporal Dependencies in Multimodal Referring Expressions with Mixed Reality
Paper and Code
Feb 04, 2019
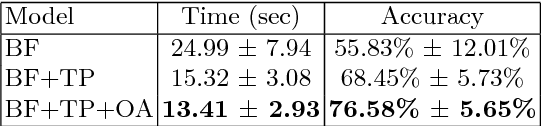
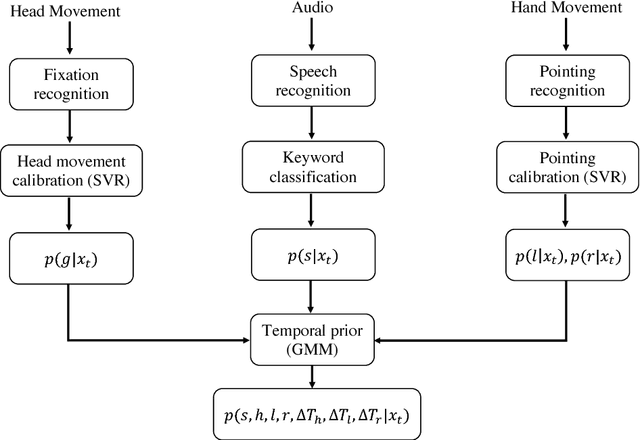

In collaborative tasks, people rely both on verbal and non-verbal cues simultaneously to communicate with each other. For human-robot interaction to run smoothly and naturally, a robot should be equipped with the ability to robustly disambiguate referring expressions. In this work, we propose a model that can disambiguate multimodal fetching requests using modalities such as head movements, hand gestures, and speech. We analysed the acquired data from mixed reality experiments and formulated a hypothesis that modelling temporal dependencies of events in these three modalities increases the model's predictive power. We evaluated our model on a Bayesian framework to interpret referring expressions with and without exploiting a temporal prior.