 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombinational Q-Learning for Dou Di Zhu
Paper and Code
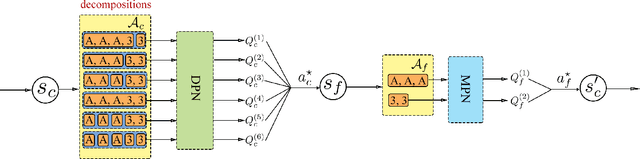
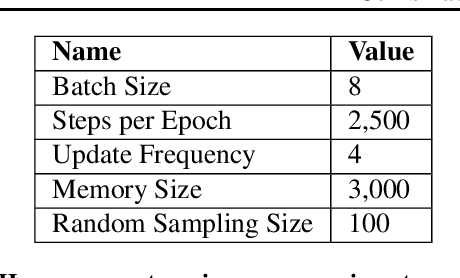
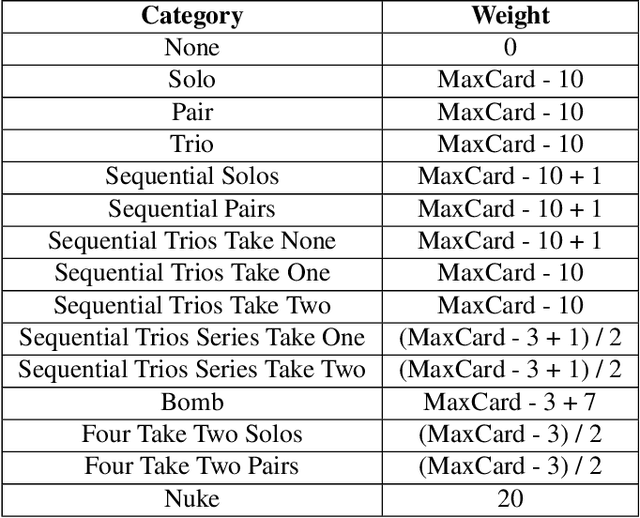
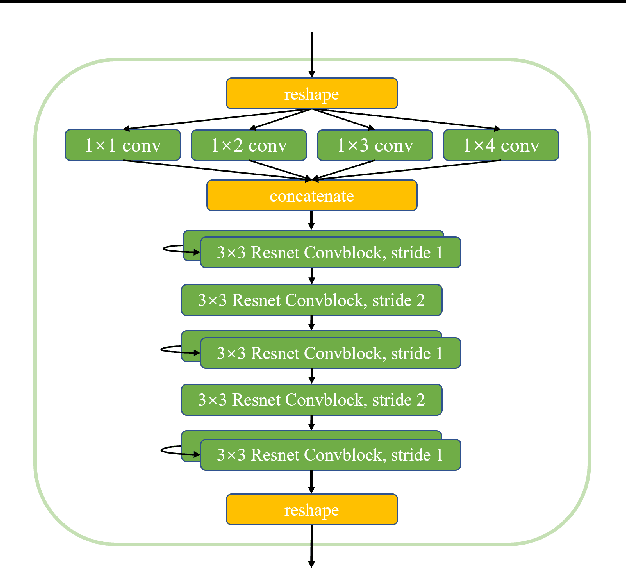
Deep reinforcement learning (DRL) has gained a lot of attention in recent years, and has been proven to be able to play Atari games and Go at or above human levels. However, those games are assumed to have a small fixed number of actions and could be trained with a simple CNN network. In this paper, we study a special class of Asian popular card games called Dou Di Zhu, in which two adversarial groups of agents must consider numerous card combinations at each time step, leading to huge number of actions. We propose a novel method to handle combinatorial actions, which we call combinational Q-learning (CQL). We employ a two-stage network to reduce action space and also leverage order-invariant max-pooling operations to extract relationships between primitive actions. Results show that our method prevails over state-of-the art methods like naive Q-learning and A3C. We develop an easy-to-use card game environments and train all agents adversarially from sractch, with only knowledge of game rules and verify that our agents are comparative to humans. Our code to reproduce all reported results will be available online.