 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Scene Segmentation Using a Light Deep Neural Network Architecture for Autonomous Robot Navigation on Construction Sites
Paper and Code
Jan 24, 2019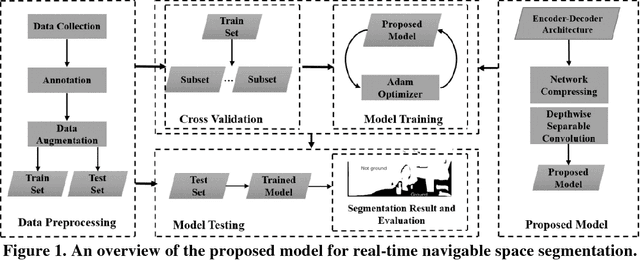
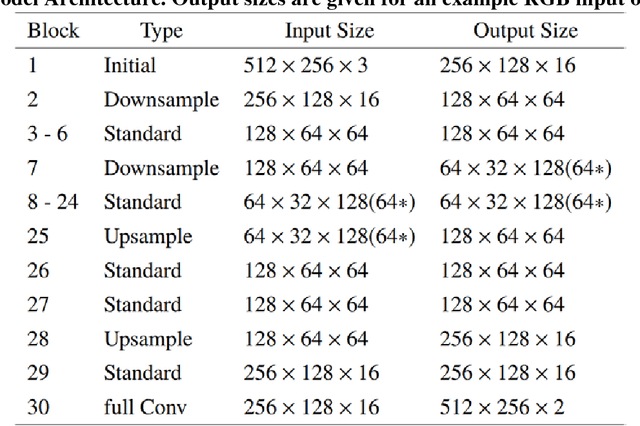
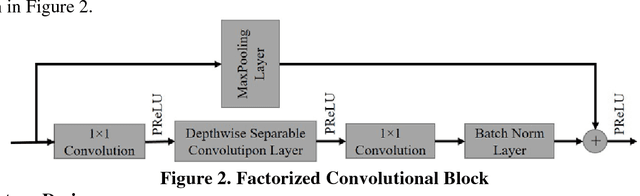
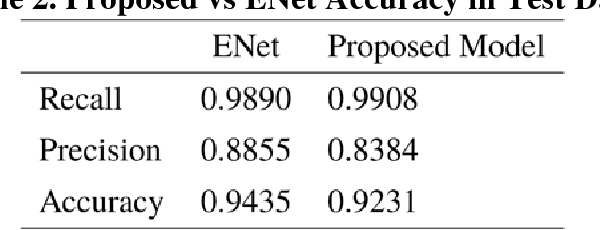
Camera-equipped unmanned vehicles (UVs) have received a lot of attention in data collection for construction monitoring applications. To develop an autonomous platform, the UV should be able to process multiple modules (e.g., context-awareness, control, localization, and mapping) on an embedded platform. Pixel-wise semantic segmentation provides a UV with the ability to be contextually aware of its surrounding environment. However, in the case of mobile robotic systems with limited computing resources, the large size of the segmentation model and high memory usage requires high computing resources, which a major challenge for mobile UVs (e.g., a small-scale vehicle with limited payload and space). To overcome this challenge, this paper presents a light and efficient deep neural network architecture to run on an embedded platform in real-time. The proposed model segments navigable space on an image sequence (i.e., a video stream), which is essential for an autonomous vehicle that is based on machine vision. The results demonstrate the performance efficiency of the proposed architecture compared to the existing models and suggest possible improvements that could make the model even more efficient, which is necessary for the future development of the autonomous robotics systems.