 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecision Highway for Ultra Low-Precision Quantization
Paper and Code
Dec 24, 2018
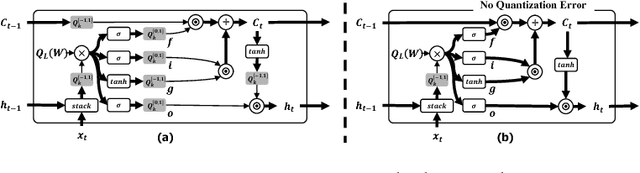

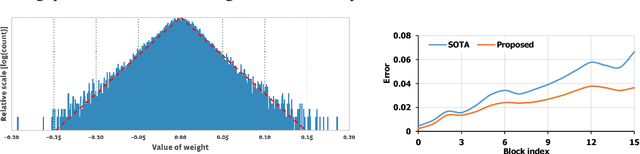
Neural network quantization has an inherent problem called accumulated quantization error, which is the key obstacle towards ultra-low precision, e.g., 2- or 3-bit precision. To resolve this problem, we propose precision highway, which forms an end-to-end high-precision information flow while performing the ultra low-precision computation. First, we describe how the precision highway reduce the accumulated quantization error in both convolutional and recurrent neural networks. We also provide the quantitative analysis of the benefit of precision highway and evaluate the overhead on the state-of-the-art hardware accelerator. In the experiments, our proposed method outperforms the best existing quantization methods while offering 3-bit weight/activation quantization with no accuracy loss and 2-bit quantization with a 2.45 % top-1 accuracy loss in ResNet-50. We also report that the proposed method significantly outperforms the existing method in the 2-bit quantization of an LSTM for language modeling.