 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiCANet: Pixel-wise Contextual Attention Learning for Accurate Saliency Detection
Paper and Code

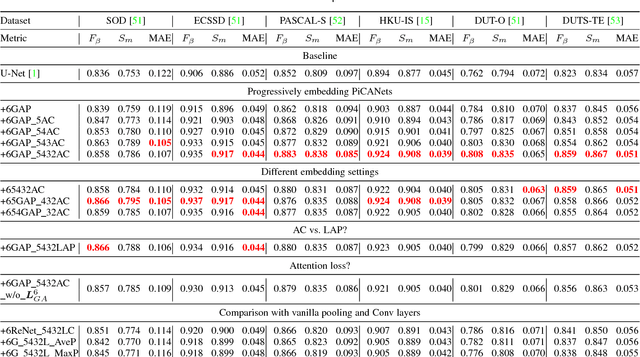
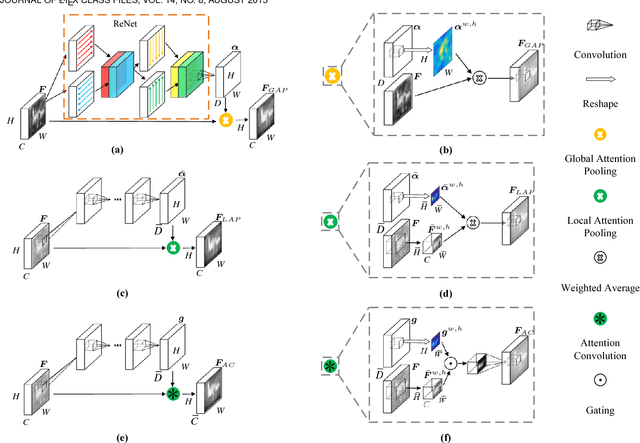
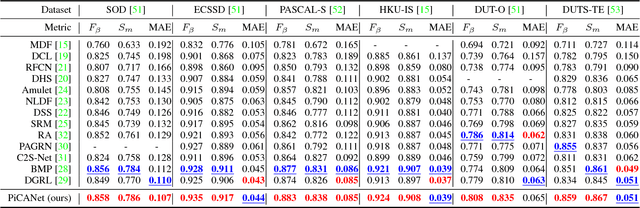
In saliency detection, every pixel needs contextual information to make saliency prediction. Previous models usually incorporate contexts holistically. However, for each pixel, usually only part of its context region is useful and contributes to its prediction, while some other part may serve as noises and distractions. In this paper, we propose a novel pixel-wise contextual attention network, \ie PiCANet, to learn to selectively attend to informative context locations at each pixel. Specifically, PiCANet generates an attention map over the context region of each pixel, where each attention weight corresponds to the relevance of a context location w.r.t the referred pixel. Then, attentive contextual features can be constructed via selectively incorporating the features of useful context locations with the learned attention. We propose three specific formulations of the PiCANet via embedding the pixel-wise contextual attention mechanism into the pooling and convolution operations with attending to global or local contexts. All the three models are fully differentiable and can be integrated with CNNs with joint training. We introduce the proposed PiCANets into a U-Net architecture for salient object detection. Experimental results indicate that the proposed PiCANets can significantly improve the saliency detection performance. The generated global and local attention can learn to incorporate global contrast and smoothness, respectively, which help localize salient objects more accurately and highlight them more uniformly. Consequently, our saliency model performs favorably against other state-of-the-art methods. Moreover, we also validate that PiCANets can also improve semantic segmentation and object detection performances, which further demonstrates their effectiveness and generalization ability.