 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethink and Redesign Meta learning
Paper and Code
Dec 24, 2018
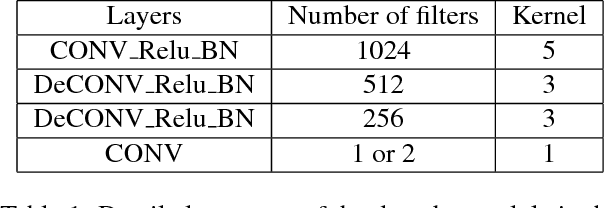
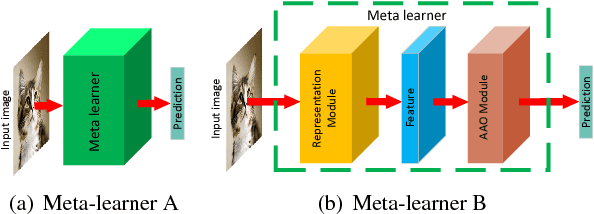
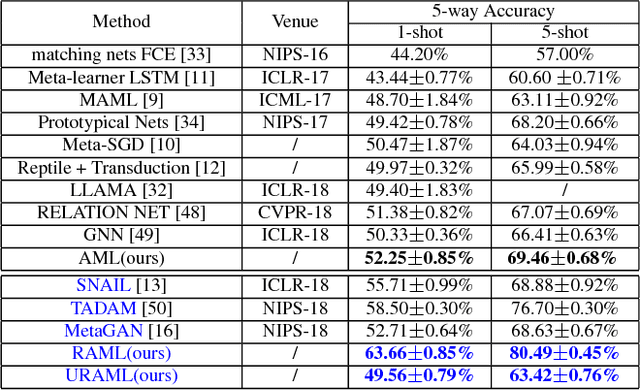
Recently, meta-learning has shown as a promising way to improve the ability to learn from few-data for many computer vision tasks. However, existing meta-learning approaches still fall behind human greatly, and like many deep learning algorithms, they also suffer from overfitting. We named this problem as Task-Over-Fitting (TOF) problem that the meta-learner over-fits to the training tasks, not to the training data. We human beings can learn from few-data, mainly due to that we are so smart to leverage past knowledge to understand the images of new categories rapidly. Furthermore, be benefiting from our flexible attention mechanism, we can accurately extract and select key features from images and further solve few-shot learning tasks with excellent performance. In this paper, we rethink the meta-learning algorithm and find that existing meta-learning approaches miss considering attention mechanism and past knowledge. To this end, we present a novel paradigm of meta-learning approach with three developments to introduce attention mechanism and past knowledge step by step. In this way, we can narrow the problem space and improve the performance of meta-learning, and the TOF problem can also be significantly reduced. Extensive experiments demonstrate the effectiveness of our designation and methods with state-of-the-art performance not only on several few-shot learning benchmarks but also on the Cross-Entropy across Tasks (CET) metric.