 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Propagation and Generation for Video Prediction
Paper and Code
Dec 02, 2018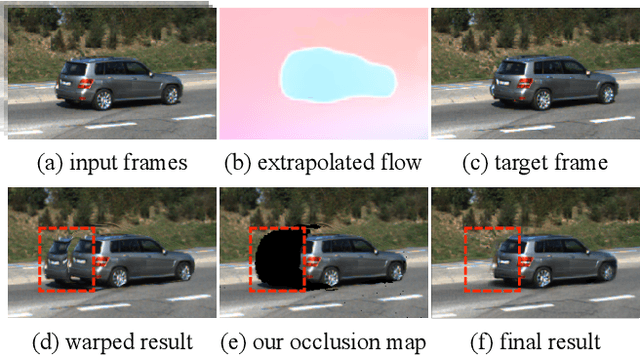
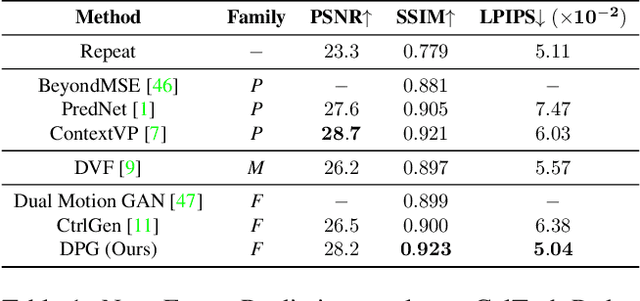
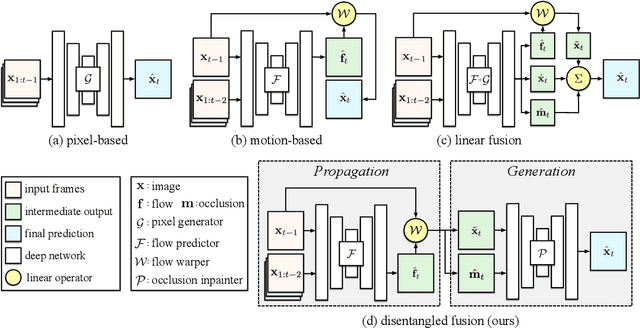
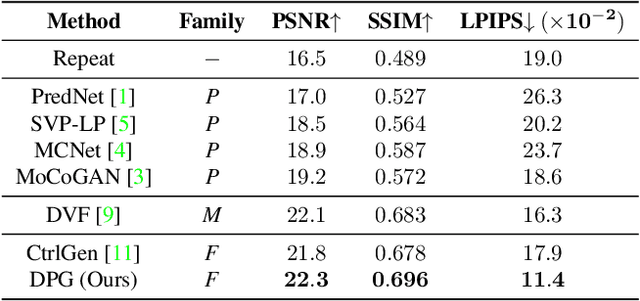
Learning to predict future video frames is a challenging task. Recent approaches for natural scenes directly predict pixels via inferring appearance flow and using flow-guided warping. Such models excel when motion estimates are accurate, but the motion may be ambiguous or erroneous in many real scenes. When scene motion exposes new regions of the scene, motion-based prediction yields poor results. However, learning to predict novel pixels directly can also require a prohibitive amount of training. In this work, we present a confidence-aware spatial-temporal context encoder for video prediction called Flow-Grounded Video Prediction (FGVP), in which motion propagation and novel pixel generation are first disentangled and then fused according to computed flow uncertainty map. For regions where motion-based prediction shows low-confidence, our model uses a conditional context encoder to hallucinate appropriate content. We test our methods on the standard CalTech Pedestrian dataset and the more challenging KITTI Flow dataset of larger motions and occlusions. Our methods produce both sharp and natural predictions compared to previous works, achieving the state-of-the-art performance on both datasets.