 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizable Object Reconstruction from a Single View
Paper and Code
Nov 29, 2018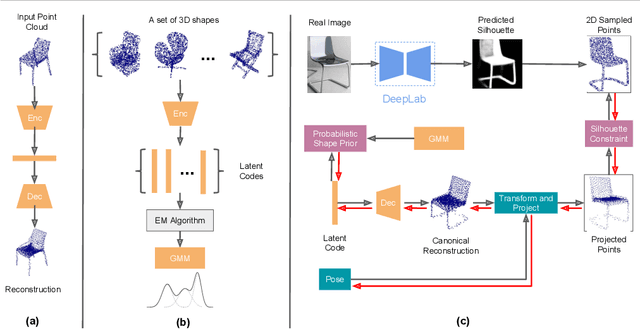
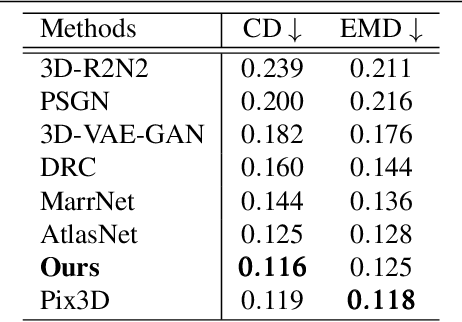


3D shape reconstruction from a single image is a highly ill-posed problem. A number of current deep learning based systems aim to solve the shape reconstruction and shape pose problems by learning an end-to-end network to perform feed-forward inference. More traditional (non-deep learning) methods cast the problem in an iterative optimization framework. In this paper, inspired by these more traditional shape-prior-based approaches, which separate the 2D recognition and 3D reconstruction, we develop a system that leverages the power of both feed-forward and iterative approaches. Our framework uses the power of deep learning to capture 3D shape information from training data and provide high-quality initialization, while allowing both image evidence and shape priors to influence iterative refinement at inference time. Specifically, we employ an auto-encoder to learn a latent space of object shapes, a CNN that maps an image to the latent space, another CNN to predict 2D keypoints to recover object pose using PnP, and a segmentation network to predict an object's silhouette from an RGB image. At inference time these components provide high-quality initial estimates of the shape and pose, which are then further optimized based on the silhouette-shape constraint and a probabilistic shape prior learned on the latent space. Our experiments show that this optimizable inference framework achieves state-of-the-art results on a large benchmarking dataset with real images.