 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocally-Consistent Deformable Convolution Networks for Fine-Grained Action Detection
Paper and Code

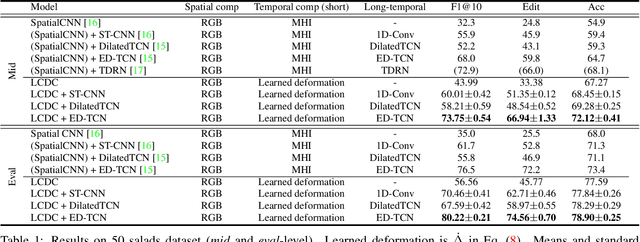
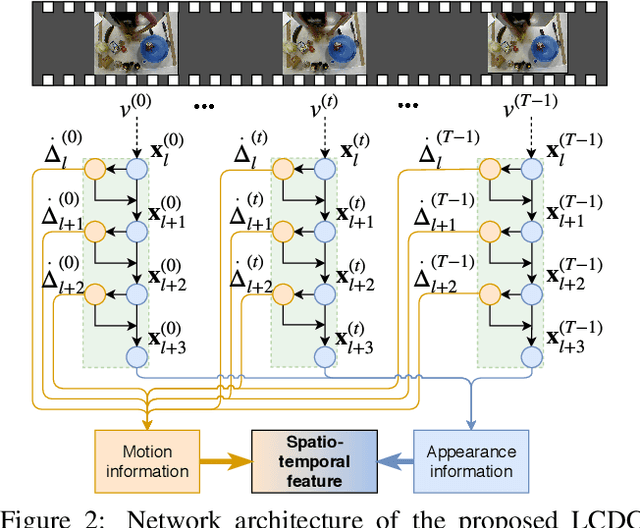
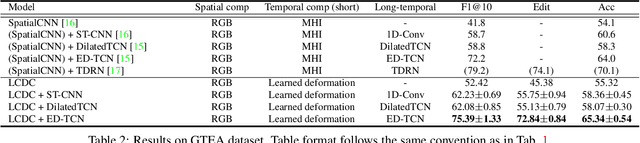
Fine-grained action detection is an important task with numerous applications in robotics, human-computer interaction, and video surveillance. Several existing methods use the popular two-stream approach, which learns the spatial and temporal information independently from one another. Additionally, the temporal stream of the model usually relies on extracted optical flow from the video stream. In this work, we propose a deep learning model to jointly learn both spatial and temporal information without the necessity of optical flow. We also propose a novel convolution, namely locally-consistent deformable convolution, which enforces a local coherency constraint on the receptive fields. The model produces short-term spatio-temporal features, which can be flexibly used in conjunction with other long-temporal modeling networks. The proposed features used in conjunction with a major state-of-the-art long-temporal model ED-TCN outperforms the original ED-TCN implementation on two fine-grained action datasets: 50 Salads and GTEA, by up to 10.0% and 4.3%, and also outperforms the recent state-of-the-art TDRN, by up to 5.9% and 2.6%.