 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Learning for Look-ahead Exploration in Continuous Control
Paper and Code
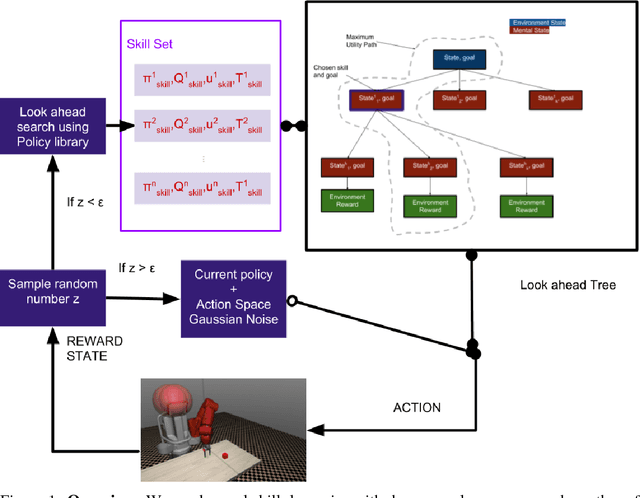
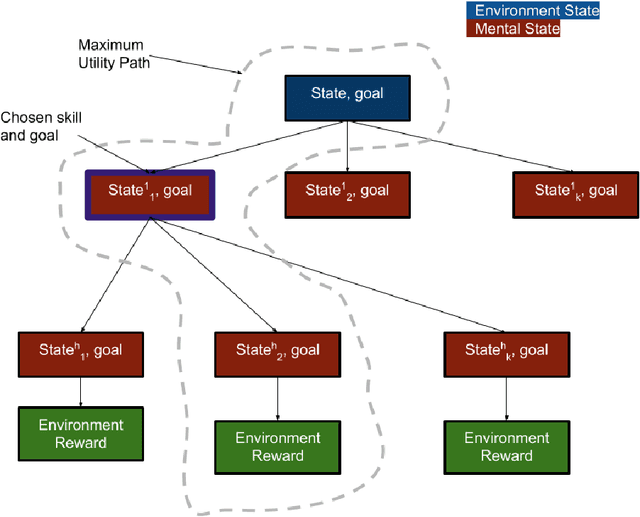
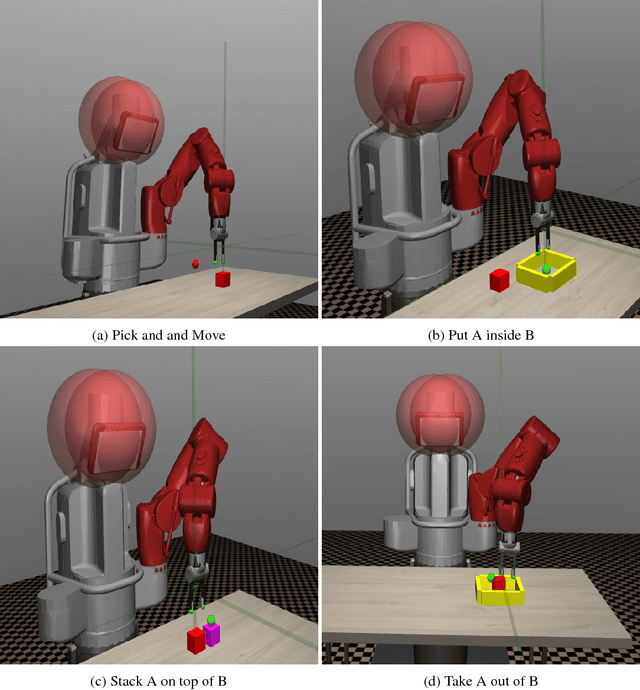
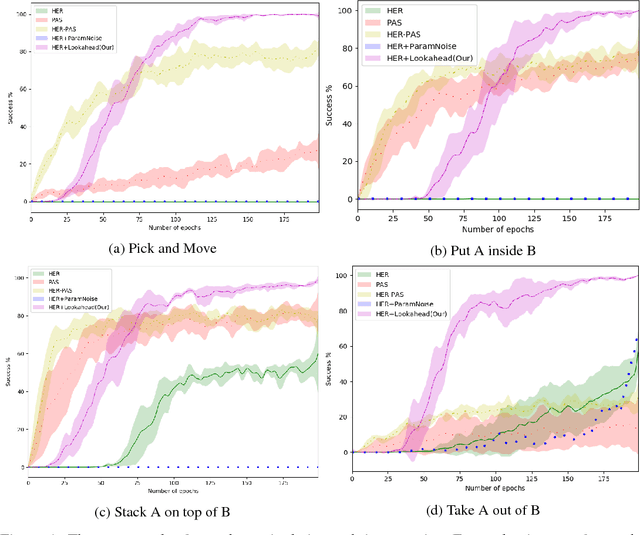
We propose an exploration method that incorporates look-ahead search over basic learnt skills and their dynamics, and use it for reinforcement learning (RL) of manipulation policies . Our skills are multi-goal policies learned in isolation in simpler environments using existing multigoal RL formulations, analogous to options or macroactions. Coarse skill dynamics, i.e., the state transition caused by a (complete) skill execution, are learnt and are unrolled forward during lookahead search. Policy search benefits from temporal abstraction during exploration, though itself operates over low-level primitive actions, and thus the resulting policies does not suffer from suboptimality and inflexibility caused by coarse skill chaining. We show that the proposed exploration strategy results in effective learning of complex manipulation policies faster than current state-of-the-art RL methods, and converges to better policies than methods that use options or parametrized skills as building blocks of the policy itself, as opposed to guiding exploration. We show that the proposed exploration strategy results in effective learning of complex manipulation policies faster than current state-of-the-art RL methods, and converges to better policies than methods that use options or parameterized skills as building blocks of the policy itself, as opposed to guiding exploration.