 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning for Multi-objective Reinforcement Learning
Paper and Code
Nov 08, 2018
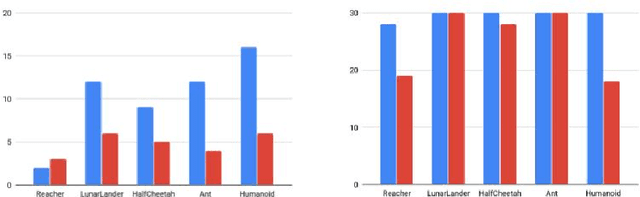
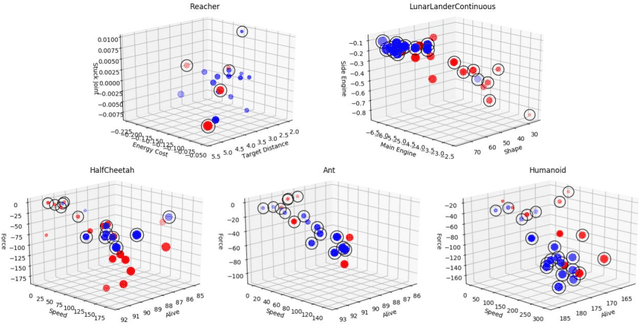
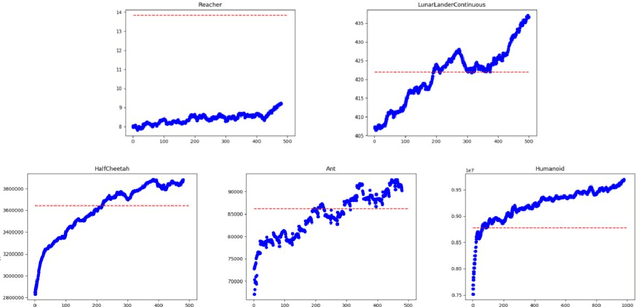
Multi-objective reinforcement learning (MORL) is the generalization of standard reinforcement learning (RL) approaches to solve sequential decision making problems that consist of several, possibly conflicting, objectives. Generally, in such formulations, there is no single optimal policy which optimizes all the objectives simultaneously, and instead, a number of policies has to be found, each optimizing a preference of the objectives. In this paper, we introduce a novel MORL approach by training a meta-policy, a policy simultaneously trained with multiple tasks sampled from a task distribution, for a number of randomly sampled Markov decision processes (MDPs). In other words, the MORL is framed as a meta-learning problem, with the task distribution given by a distribution over the preferences. We demonstrate that such a formulation results in a better approximation of the Pareto optimal solutions, in terms of both the optimality and the computational efficiency. We evaluated our method on obtaining Pareto optimal policies using a number of continuous control problems with high degrees of freedom.