 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Weakly Supervised Data to Improve End-to-End Speech-to-Text Translation
Paper and Code
Nov 05, 2018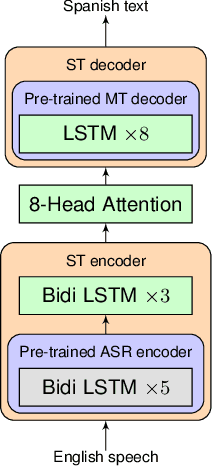

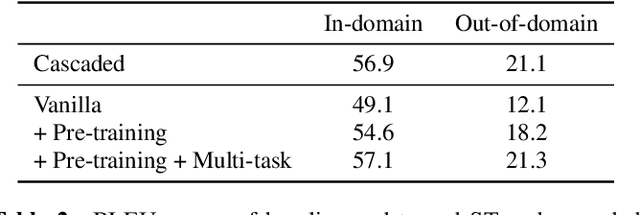
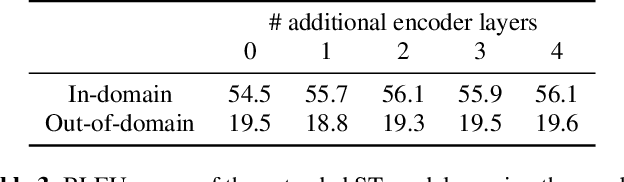
End-to-end Speech Translation (ST) models have many potential advantages when compared to the cascade of Automatic Speech Recognition (ASR) and text Machine Translation (MT) models, including lowered inference latency and the avoidance of error compounding. However, the quality of end-to-end ST is often limited by a paucity of training data, since it is difficult to collect large parallel corpora of speech and translated transcript pairs. Previous studies have proposed the use of pre-trained components and multi-task learning in order to benefit from weakly supervised training data, such as speech-to-transcript or text-to-foreign-text pairs. In this paper, we demonstrate that using pre-trained MT or text-to-speech (TTS) synthesis models to convert weakly supervised data into speech-to-translation pairs for ST training can be more effective than multi-task learning. Furthermore, we demonstrate that a high quality end-to-end ST model can be trained using only weakly supervised datasets, and that synthetic data sourced from unlabeled monolingual text or speech can be used to improve performance. Finally, we discuss methods for avoiding overfitting to synthetic speech with a quantitative ablation study.