 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Shot Hierarchical Imitation Learning of Compound Visuomotor Tasks
Paper and Code
Oct 25, 2018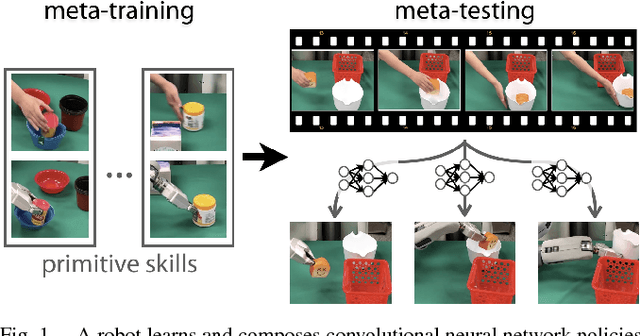
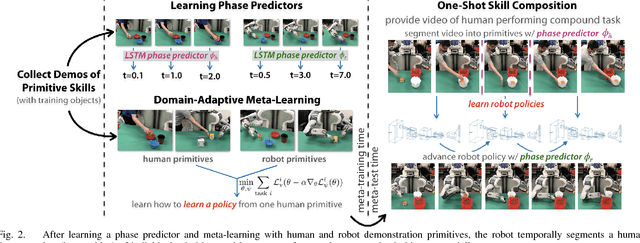


We consider the problem of learning multi-stage vision-based tasks on a real robot from a single video of a human performing the task, while leveraging demonstration data of subtasks with other objects. This problem presents a number of major challenges. Video demonstrations without teleoperation are easy for humans to provide, but do not provide any direct supervision. Learning policies from raw pixels enables full generality but calls for large function approximators with many parameters to be learned. Finally, compound tasks can require impractical amounts of demonstration data, when treated as a monolithic skill. To address these challenges, we propose a method that learns both how to learn primitive behaviors from video demonstrations and how to dynamically compose these behaviors to perform multi-stage tasks by "watching" a human demonstrator. Our results on a simulated Sawyer robot and real PR2 robot illustrate our method for learning a variety of order fulfillment and kitchen serving tasks with novel objects and raw pixel inputs.