 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIT: Block-wise Intermediate Representation Training for Model Compression
Paper and Code
Oct 02, 2018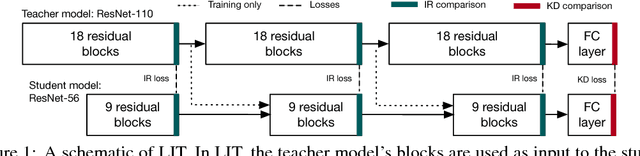

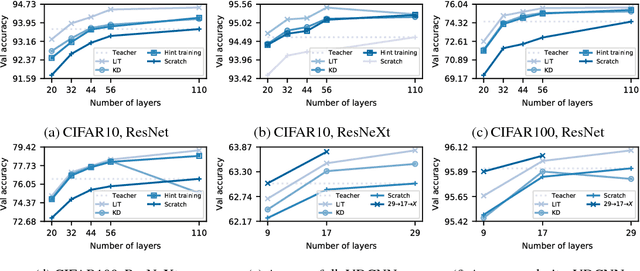

Knowledge distillation (KD) is a popular method for reducing the computational overhead of deep network inference, in which the output of a teacher model is used to train a smaller, faster student model. Hint training (i.e., FitNets) extends KD by regressing a student model's intermediate representation to a teacher model's intermediate representation. In this work, we introduce bLock-wise Intermediate representation Training (LIT), a novel model compression technique that extends the use of intermediate representations in deep network compression, outperforming KD and hint training. LIT has two key ideas: 1) LIT trains a student of the same width (but shallower depth) as the teacher by directly comparing the intermediate representations, and 2) LIT uses the intermediate representation from the previous block in the teacher model as an input to the current student block during training, avoiding unstable intermediate representations in the student network. We show that LIT provides substantial reductions in network depth without loss in accuracy -- for example, LIT can compress a ResNeXt-110 to a ResNeXt-20 (5.5x) on CIFAR10 and a VDCNN-29 to a VDCNN-9 (3.2x) on Amazon Reviews without loss in accuracy, outperforming KD and hint training in network size for a given accuracy. We also show that applying LIT to identical student/teacher architectures increases the accuracy of the student model above the teacher model, outperforming the recently-proposed Born Again Networks procedure on ResNet, ResNeXt, and VDCNN. Finally, we show that LIT can effectively compress GAN generators, which are not supported in the KD framework because GANs output pixels as opposed to probabilities.