 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Oriented Hand Motion Retargeting for Dexterous Manipulation Imitation
Paper and Code
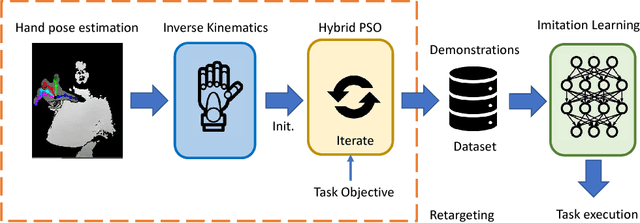
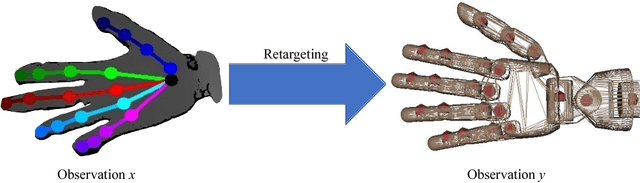
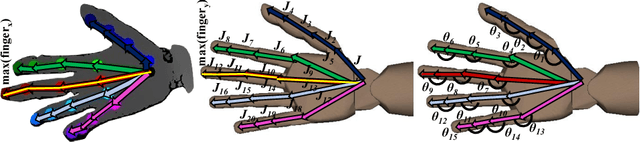
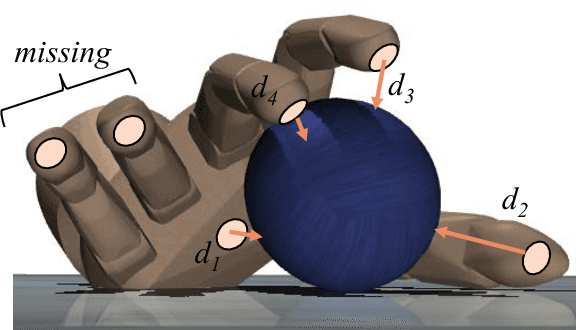
Human hand actions are quite complex, especially when they involve object manipulation, mainly due to the high dimensionality of the hand and the vast action space that entails. Imitating those actions with dexterous hand models involves different important and challenging steps: acquiring human hand information, retargeting it to a hand model, and learning a policy from acquired data. In this work, we capture the hand information by using a state-of-the-art hand pose estimator. We tackle the retargeting problem from the hand pose to a 29 DoF hand model by combining inverse kinematics and PSO with a task objective optimisation. This objective encourages the virtual hand to accomplish the manipulation task, relieving the effect of the estimator's noise and the domain gap. Our approach leads to a better success rate in the grasping task compared to our inverse kinematics baseline, allowing us to record successful human demonstrations. Furthermore, we used these demonstrations to learn a policy network using generative adversarial imitation learning (GAIL) that is able to autonomously grasp an object in the virtual space.