Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Implicit Online Learning
Paper and Code
Oct 14, 2018
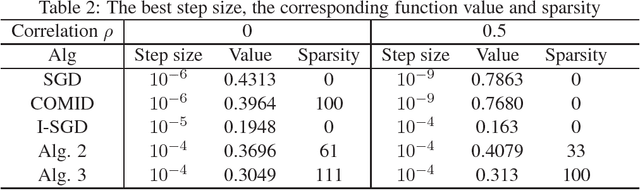
Regularized online learning is widely used in machine learning applications. In this paper we analyze a class of regularized online algorithms without linearizing the loss function or the regularizer, which we call \emph{fully implicit online learning} (FIOL). We show that the FIOL algorithm admits a better regret than the linearization approximate algorithm if each iteration in FIOL can be solved exactly. Then we show that by exploring the structure of a large class of loss functions and regularizers, the computational complexity of FIOL in each iteration is comparable to its linearized part, even if no closed-form solution exists. Experiments validate the proposed approaches.
* 17 pages
View paper on