 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Judgment Prediction via Legal Reading Comprehension
Paper and Code
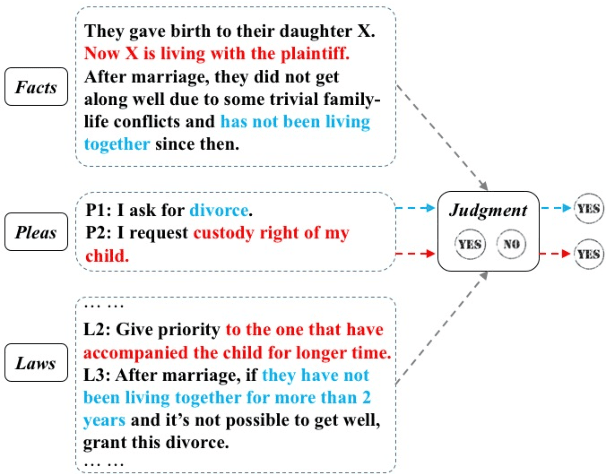
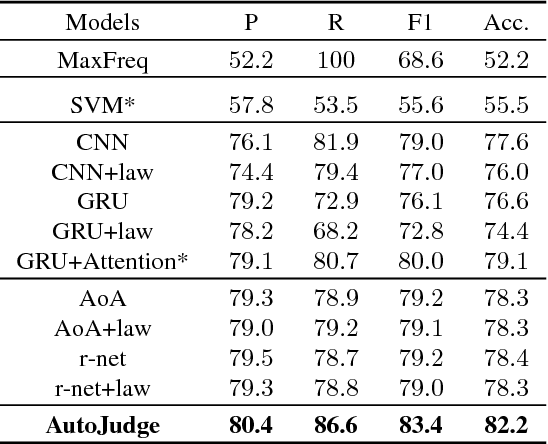
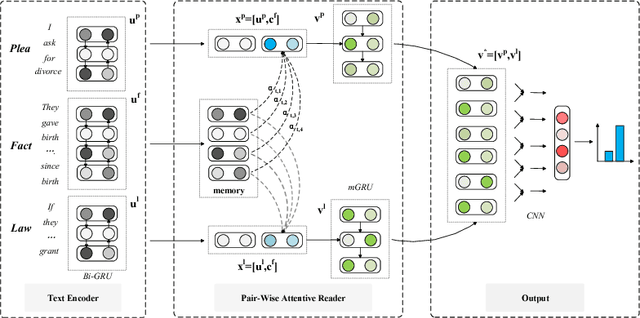
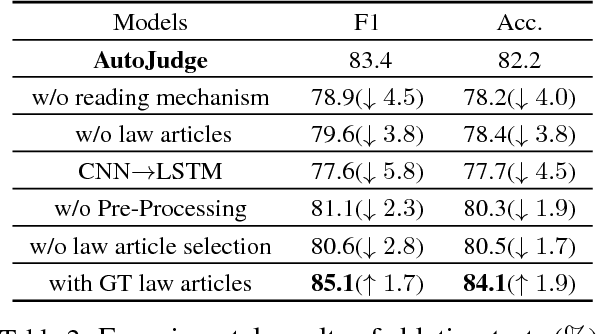
Automatic judgment prediction aims to predict the judicial results based on case materials. It has been studied for several decades mainly by lawyers and judges, considered as a novel and prospective application of artificial intelligence techniques in the legal field. Most existing methods follow the text classification framework, which fails to model the complex interactions among complementary case materials. To address this issue, we formalize the task as Legal Reading Comprehension according to the legal scenario. Following the working protocol of human judges, LRC predicts the final judgment results based on three types of information, including fact description, plaintiffs' pleas, and law articles. Moreover, we propose a novel LRC model, AutoJudge, which captures the complex semantic interactions among facts, pleas, and laws. In experiments, we construct a real-world civil case dataset for LRC. Experimental results on this dataset demonstrate that our model achieves significant improvement over state-of-the-art models. We will publish all source codes and datasets of this work on \urlgithub.com for further research.