 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden Markov Model Estimation-Based Q-learning for Partially Observable Markov Decision Process
Paper and Code
Sep 24, 2018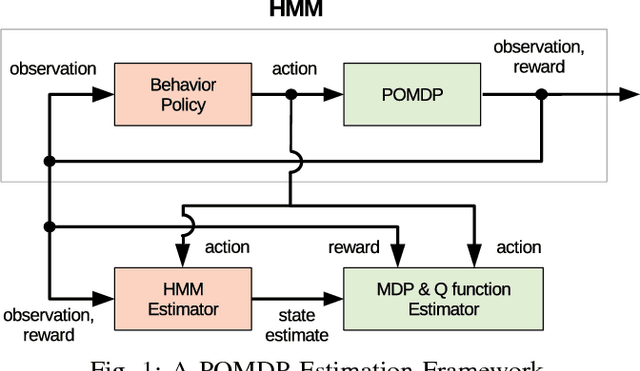
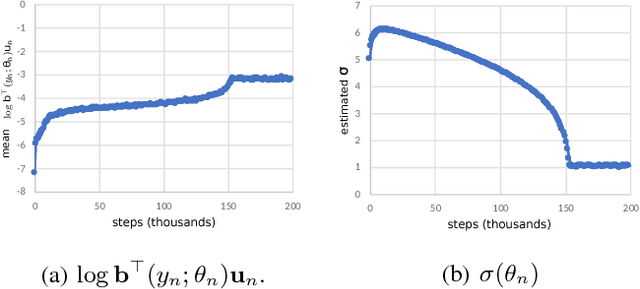
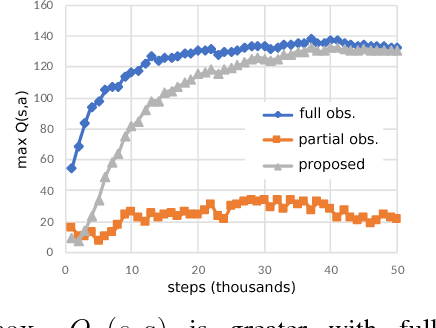
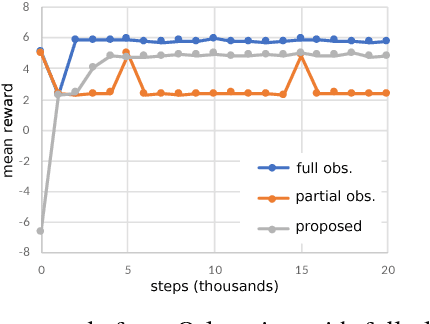
The objective is to study an on-line Hidden Markov model (HMM) estimation-based Q-learning algorithm for partially observable Markov decision process (POMDP) on finite state and action sets. When the full state observation is available, Q-learning finds the optimal action-value function given the current action (Q function). However, Q-learning can perform poorly when the full state observation is not available. In this paper, we formulate the POMDP estimation into a HMM estimation problem and propose a recursive algorithm to estimate both the POMDP parameter and Q function concurrently. Also, we show that the POMDP estimation converges to a set of stationary points for the maximum likelihood estimate, and the Q function estimation converges to a fixed point that satisfies the Bellman optimality equation weighted on the invariant distribution of the state belief determined by the HMM estimation process.