 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStacked Pooling: Improving Crowd Counting by Boosting Scale Invariance
Paper and Code


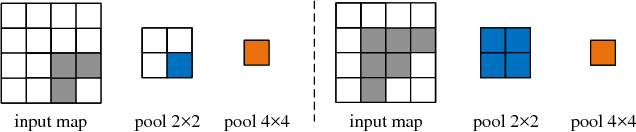
In this work, we explore the cross-scale similarity in crowd counting scenario, in which the regions of different scales often exhibit high visual similarity. This feature is universal both within an image and across different images, indicating the importance of scale invariance of a crowd counting model. Motivated by this, in this paper we propose simple but effective variants of pooling module, i.e., multi-kernel pooling and stacked pooling, to boost the scale invariance of convolutional neural networks (CNNs), benefiting much the crowd density estimation and counting. Specifically, the multi-kernel pooling comprises of pooling kernels with multiple receptive fields to capture the responses at multi-scale local ranges. The stacked pooling is an equivalent form of multi-kernel pooling, while, it reduces considerable computing cost. Our proposed pooling modules do not introduce extra parameters into model and can easily take place of the vanilla pooling layer in implementation. In empirical study on two benchmark crowd counting datasets, the stacked pooling beats the vanilla pooling layer in most cases.