 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeyphrase Generation with Correlation Constraints
Paper and Code

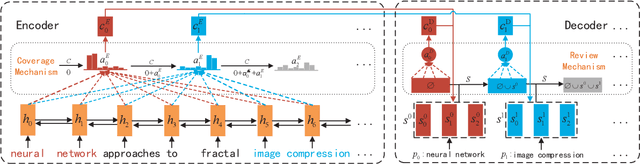
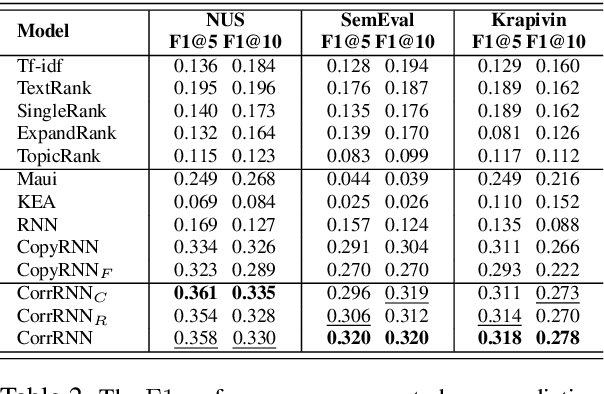

In this paper, we study automatic keyphrase generation. Although conventional approaches to this task show promising results, they neglect correlation among keyphrases, resulting in duplication and coverage issues. To solve these problems, we propose a new sequence-to-sequence architecture for keyphrase generation named CorrRNN, which captures correlation among multiple keyphrases in two ways. First, we employ a coverage vector to indicate whether the word in the source document has been summarized by previous phrases to improve the coverage for keyphrases. Second, preceding phrases are taken into account to eliminate duplicate phrases and improve result coherence. Experiment results show that our model significantly outperforms the state-of-the-art method on benchmark datasets in terms of both accuracy and diversity.