 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlended Coarse Gradient Descent for Full Quantization of Deep Neural Networks
Paper and Code
Aug 29, 2018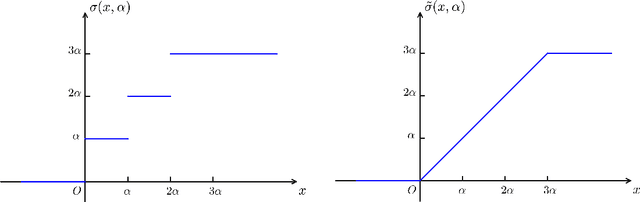
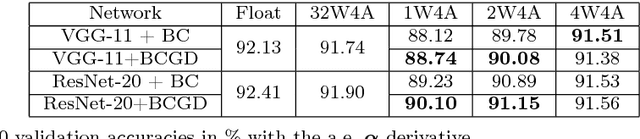
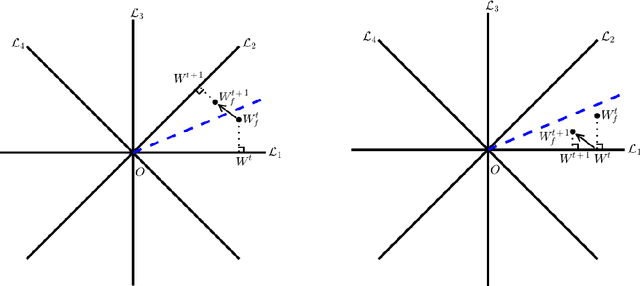
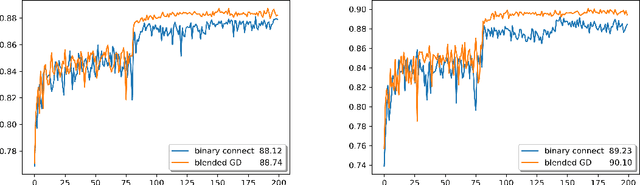
Quantized deep neural networks (QDNNs) are attractive due to their much lower memory storage and faster inference speed than their regular full precision counterparts. To maintain the same performance level especially at low bit-widths, QDNNs must be retrained. Their training involves piecewise constant activation functions and discrete weights, hence mathematical challenges arise. We introduce the notion of coarse derivative and propose the blended coarse gradient descent (BCGD) algorithm, for training fully quantized neural networks. Coarse gradient is generally not a gradient of any function but an artificial ascent direction. The weight update of BCGD goes by coarse gradient correction of a weighted average of the full precision weights and their quantization (the so-called blending), which yields sufficient descent in the objective value and thus accelerates the training. Our experiments demonstrate that this simple blending technique is very effective for quantization at extremely low bit-width such as binarization. In full quantization of ResNet-18 for ImageNet classification task, BCGD gives 64.36% top-1 accuracy with binary weights across all layers and 4-bit adaptive activation. If the weights in the first and last layers are kept in full precision, this number increases to 65.46%. As theoretical justification, we provide the convergence analysis of coarse gradient descent for a two-layer neural network model with Gaussian input data, and prove that the expected coarse gradient correlates positively with the underlying true gradient.