 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep context: end-to-end contextual speech recognition
Paper and Code
Aug 07, 2018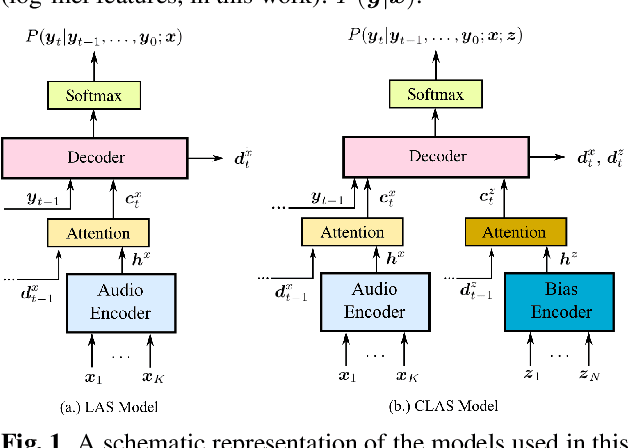
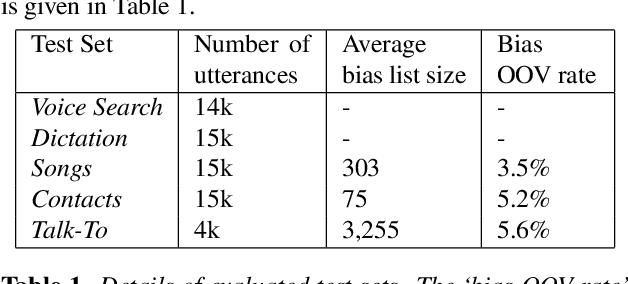
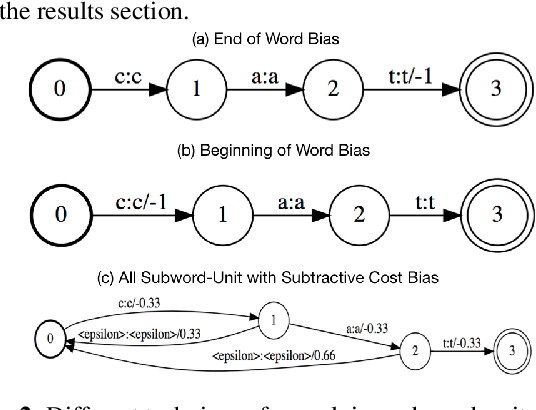
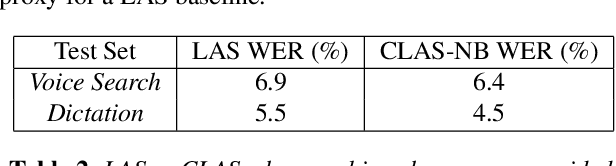
In automatic speech recognition (ASR) what a user says depends on the particular context she is in. Typically, this context is represented as a set of word n-grams. In this work, we present a novel, all-neural, end-to-end (E2E) ASR sys- tem that utilizes such context. Our approach, which we re- fer to as Contextual Listen, Attend and Spell (CLAS) jointly- optimizes the ASR components along with embeddings of the context n-grams. During inference, the CLAS system can be presented with context phrases which might contain out-of- vocabulary (OOV) terms not seen during training. We com- pare our proposed system to a more traditional contextualiza- tion approach, which performs shallow-fusion between inde- pendently trained LAS and contextual n-gram models during beam search. Across a number of tasks, we find that the pro- posed CLAS system outperforms the baseline method by as much as 68% relative WER, indicating the advantage of joint optimization over individually trained components. Index Terms: speech recognition, sequence-to-sequence models, listen attend and spell, LAS, attention, embedded speech recognition.