 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Forecast and Refine Residual Motion for Image-to-Video Generation
Paper and Code
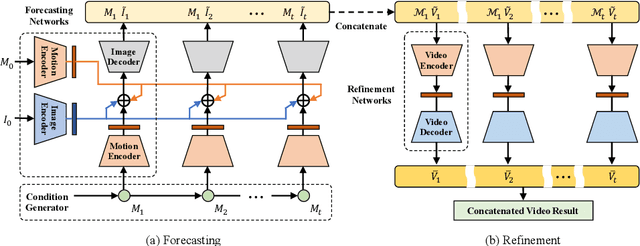
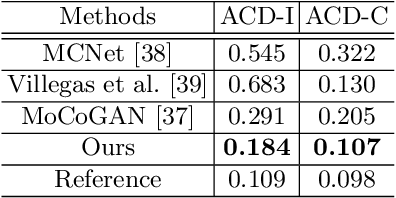
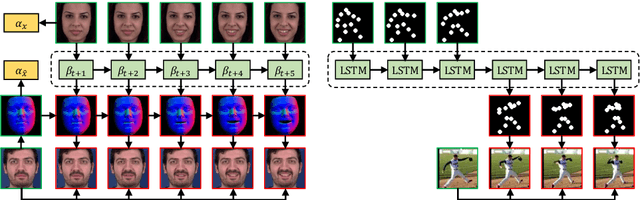
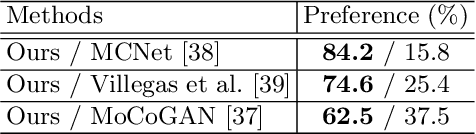
We consider the problem of image-to-video translation, where an input image is translated into an output video containing motions of a single object. Recent methods for such problems typically train transformation networks to generate future frames conditioned on the structure sequence. Parallel work has shown that short high-quality motions can be generated by spatiotemporal generative networks that leverage temporal knowledge from the training data. We combine the benefits of both approaches and propose a two-stage generation framework where videos are generated from structures and then refined by temporal signals. To model motions more efficiently, we train networks to learn residual motion between the current and future frames, which avoids learning motion-irrelevant details. We conduct extensive experiments on two image-to-video translation tasks: facial expression retargeting and human pose forecasting. Superior results over the state-of-the-art methods on both tasks demonstrate the effectiveness of our approach.