 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackplay: "Man muss immer umkehren"
Paper and Code
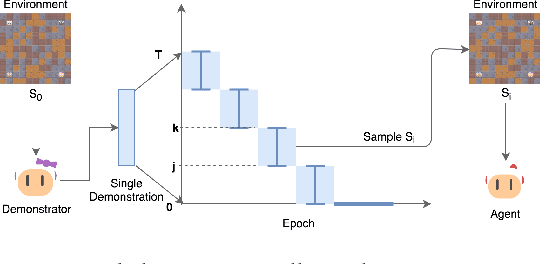
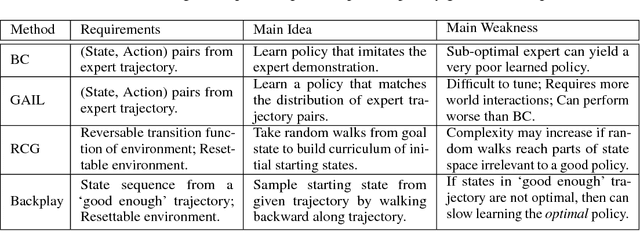
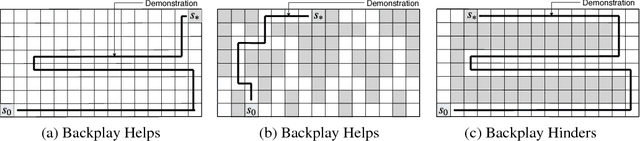
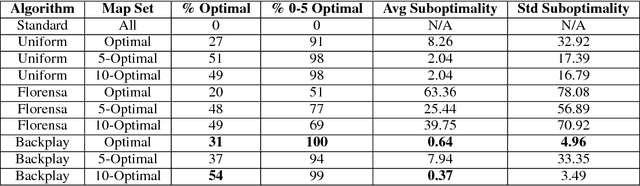
A long-standing problem in model-free reinforcement learning (RL) is that it requires a large number of trials to learn a good policy, especially in environments with sparse rewards. We explore a method to increase the sample efficiency of RL when we have access to demonstrations. Our approach, Backplay, uses a single demonstration to construct a curriculum for a given task. Rather than starting each training episode in the environment's fixed initial state, we start the agent near the end of the demonstration and move the starting point backwards during the course of training until we reach the initial state. We perform experiments in a competitive four-player game (Pommerman) and a path-finding maze game. We find that Backplay provides significant gains in sample complexity with a stark advantage in sparse reward settings. In some cases, it reached success rates greater than 50 and generalized to unseen initial conditions, while standard RL did not yield any improvement.