 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent Jumpy Predictions for Videos and Scenes
Paper and Code
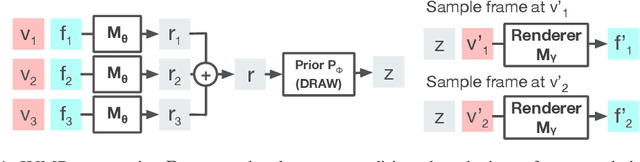
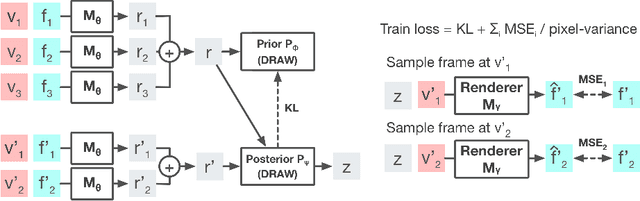


Stochastic video prediction models take in a sequence of image frames, and generate a sequence of consecutive future image frames. These models typically generate future frames in an autoregressive fashion, which is slow and requires the input and output frames to be consecutive. We introduce a model that overcomes these drawbacks by generating a latent representation from an arbitrary set of frames that can then be used to simultaneously and efficiently sample temporally consistent frames at arbitrary time-points. For example, our model can "jump" and directly sample frames at the end of the video, without sampling intermediate frames. Synthetic video evaluations confirm substantial gains in speed and functionality without loss in fidelity. We also apply our framework to a 3D scene reconstruction dataset. Here, our model is conditioned on camera location and can sample consistent sets of images for what an occluded region of a 3D scene might look like, even if there are multiple possibilities for what that region might contain. Reconstructions and videos are available at https://bit.ly/2O4Pc4R.