 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Effectiveness of Lipschitz-Continuity in Generative Adversarial Nets
Paper and Code

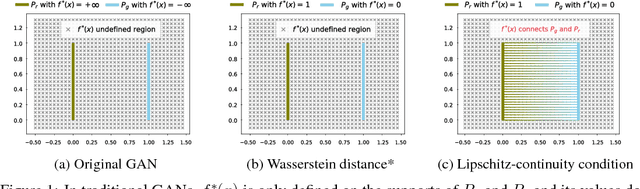
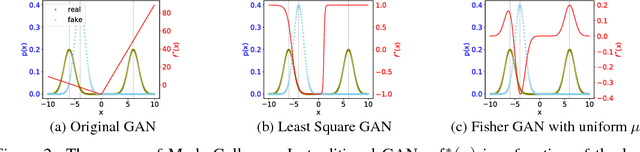
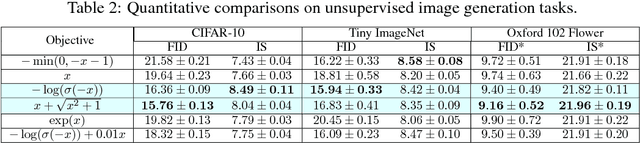
In this paper, we investigate the underlying factor that leads to the failure and success in training of GANs. Specifically, we study the property of the optimal discriminative function $f^*(x)$ and show that $f^*(x)$ in most GANs can only reflect the local densities at $x$, which means the value of $f^*(x)$ for points in the fake distribution ($P_g$) does not contain any information useful about the location of other points in the real distribution ($P_r$). Given that the supports of the real and fake distributions are usually disjoint, we argue that such a $f^*(x)$ and its gradient tell nothing about "how to pull $P_g$ to $P_r$", which turns out to be the fundamental cause of failure in training of GANs. We further demonstrate that a well-defined distance metric (including Wasserstein distance) does not necessarily ensure the convergence of GANs. Finally, we propose Lipschitz-continuity condition as a general solution and show that in a large family of GAN objectives, Lipschitz condition is capable of connecting $P_g$ and $P_r$ through $f^*(x)$ such that the gradient $\nabla_{\!x} f^*(x)$ at each sample $x \sim P_g$ points towards some real sample $y \sim P_r$.