 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructurally Sparsified Backward Propagation for Faster Long Short-Term Memory Training
Paper and Code
Jun 01, 2018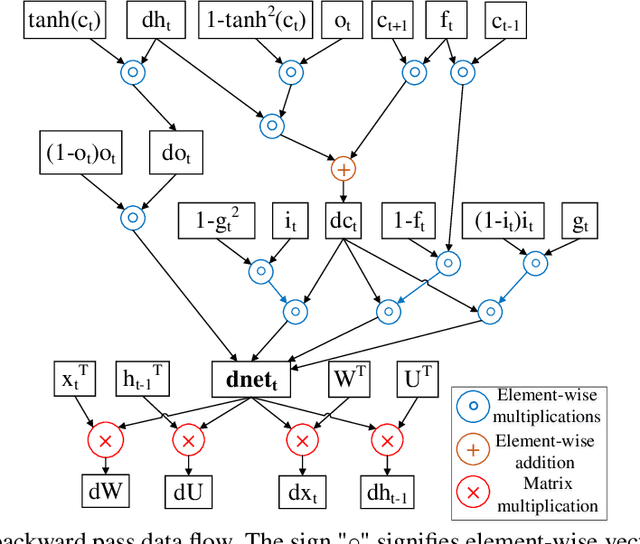
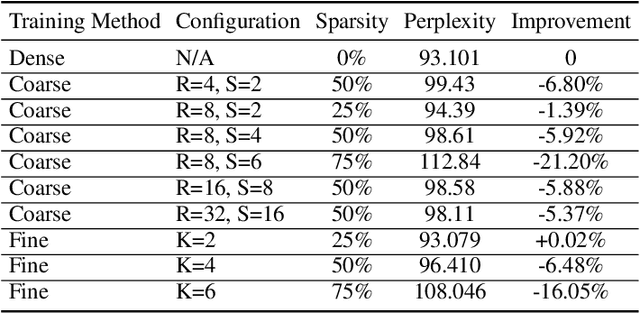
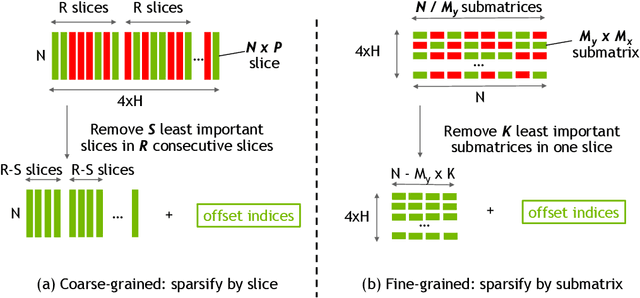
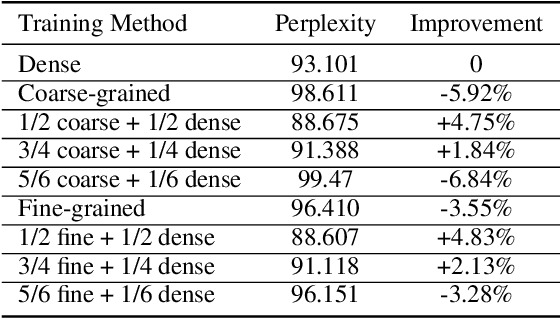
Exploiting sparsity enables hardware systems to run neural networks faster and more energy-efficiently. However, most prior sparsity-centric optimization techniques only accelerate the forward pass of neural networks and usually require an even longer training process with iterative pruning and retraining. We observe that artificially inducing sparsity in the gradients of the gates in an LSTM cell has little impact on the training quality. Further, we can enforce structured sparsity in the gate gradients to make the LSTM backward pass up to 45% faster than the state-of-the-art dense approach and 168% faster than the state-of-the-art sparsifying method on modern GPUs. Though the structured sparsifying method can impact the accuracy of a model, this performance gap can be eliminated by mixing our sparse training method and the standard dense training method. Experimental results show that the mixed method can achieve comparable results in a shorter time span than using purely dense training.