 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Parallel Recurrent Neural Networks with Convolutional Attentions for Multi-Modality Activity Modeling
Paper and Code
May 17, 2018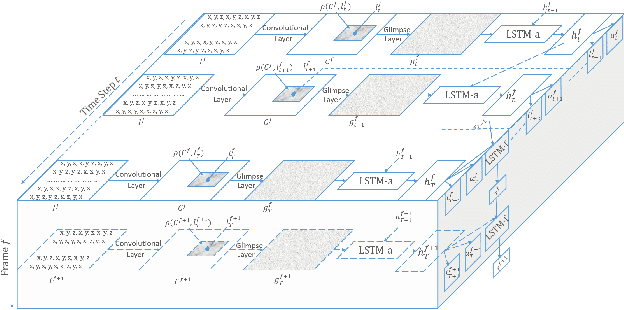
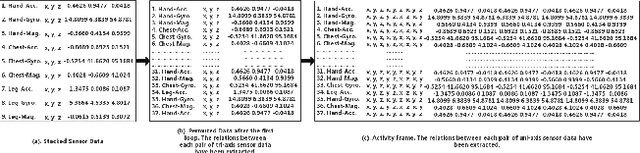
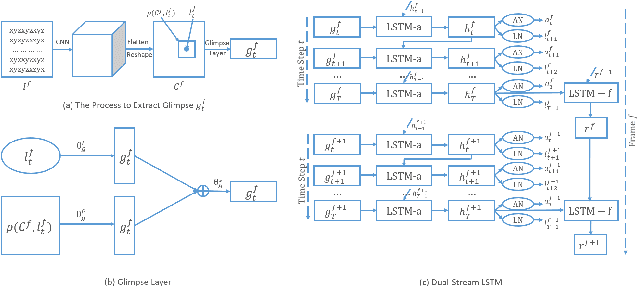
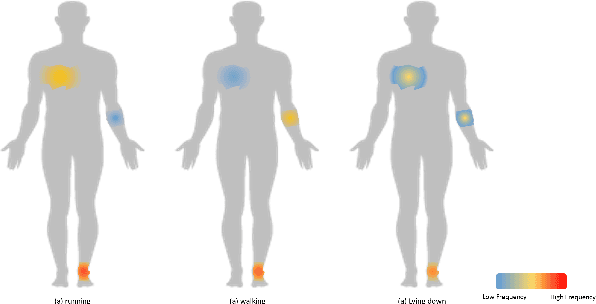
Multimodal features play a key role in wearable sensor-based human activity recognition (HAR). Selecting the most salient features adaptively is a promising way to maximize the effectiveness of multimodal sensor data. In this regard, we propose a "collect fully and select wisely" principle as well as an interpretable parallel recurrent model with convolutional attentions to improve the recognition performance. We first collect modality features and the relations between each pair of features to generate activity frames, and then introduce an attention mechanism to select the most prominent regions from activity frames precisely. The selected frames not only maximize the utilization of valid features but also reduce the number of features to be computed effectively. We further analyze the accuracy and interpretability of the proposed model based on extensive experiments. The results show that our model achieves competitive performance on two benchmarked datasets and works well in real life scenarios.