 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Global Localization with a Hybrid WNN-CNN Approach
Paper and Code

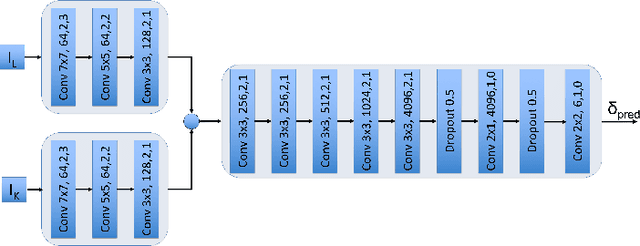
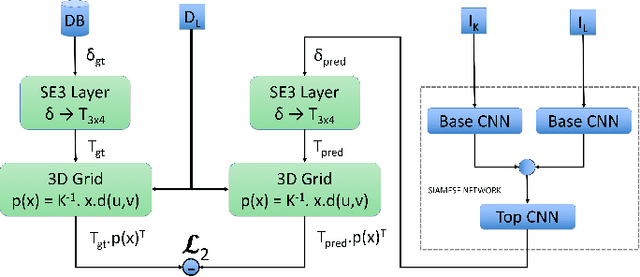
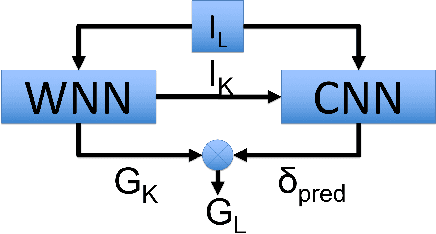
Currently, self-driving cars rely greatly on the Global Positioning System (GPS) infrastructure, albeit there is an increasing demand for alternative methods for GPS-denied environments. One of them is known as place recognition, which associates images of places with their corresponding positions. We previously proposed systems based on Weightless Neural Networks (WNN) to address this problem as a classification task. This encompasses solely one part of the global localization, which is not precise enough for driverless cars. Instead of just recognizing past places and outputting their poses, it is desired that a global localization system estimates the pose of current place images. In this paper, we propose to tackle this problem as follows. Firstly, given a live image, the place recognition system returns the most similar image and its pose. Then, given live and recollected images, a visual localization system outputs the relative camera pose represented by those images. To estimate the relative camera pose between the recollected and the current images, a Convolutional Neural Network (CNN) is trained with the two images as input and a relative pose vector as output. Together, these systems solve the global localization problem using the topological and metric information to approximate the current vehicle pose. The full approach is compared to a Real- Time Kinematic GPS system and a Simultaneous Localization and Mapping (SLAM) system. Experimental results show that the proposed approach correctly localizes a vehicle 90% of the time with a mean error of 1.20m compared to 1.12m of the SLAM system and 0.37m of the GPS, 89% of the time.