 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Attribute-augmented Three-dimensional Convolutional Neural Network for Enhanced Human Action Recognition
Paper and Code
May 08, 2018

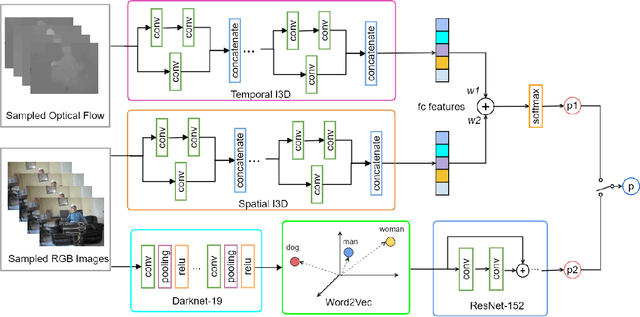
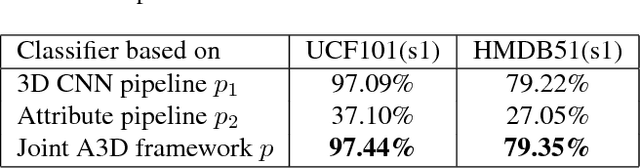
Visual attributes in individual video frames, such as the presence of characteristic objects and scenes, offer substantial information for action recognition in videos. With individual 2D video frame as input, visual attributes extraction could be achieved effectively and efficiently with more sophisticated convolutional neural network than current 3D CNNs with spatio-temporal filters, thanks to fewer parameters in 2D CNNs. In this paper, the integration of visual attributes (including detection, encoding and classification) into multi-stream 3D CNN is proposed for action recognition in trimmed videos, with the proposed visual Attribute-augmented 3D CNN (A3D) framework. The visual attribute pipeline includes an object detection network, an attributes encoding network and a classification network. Our proposed A3D framework achieves state-of-the-art performance on both the HMDB51 and the UCF101 datasets.