Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Dynamics and Reward for Transfer Learning
Paper and Code
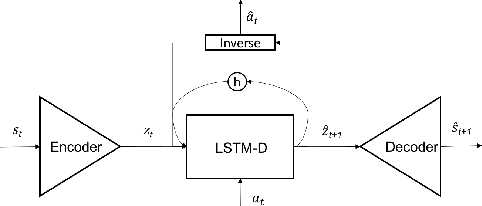
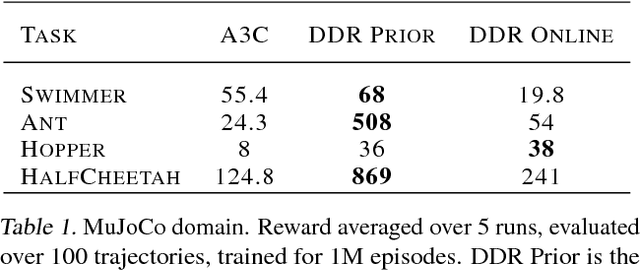
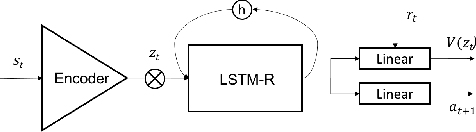
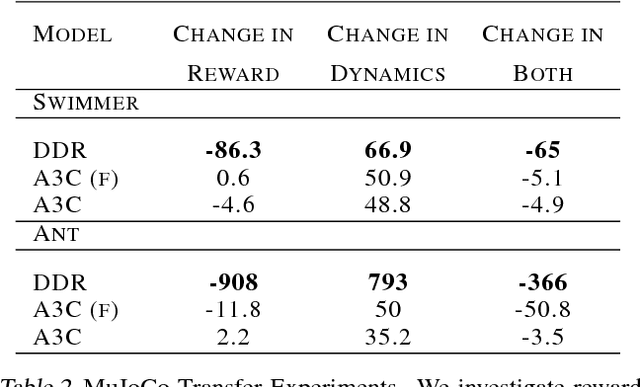
Current reinforcement learning (RL) methods can successfully learn single tasks but often generalize poorly to modest perturbations in task domain or training procedure. In this work, we present a decoupled learning strategy for RL that creates a shared representation space where knowledge can be robustly transferred. We separate learning the task representation, the forward dynamics, the inverse dynamics and the reward function of the domain, and show that this decoupling improves performance within the task, transfers well to changes in dynamics and reward, and can be effectively used for online planning. Empirical results show good performance in both continuous and discrete RL domains.
View paper on