 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task Learning for Universal Sentence Embeddings: A Thorough Evaluation using Transfer and Auxiliary Tasks
Paper and Code
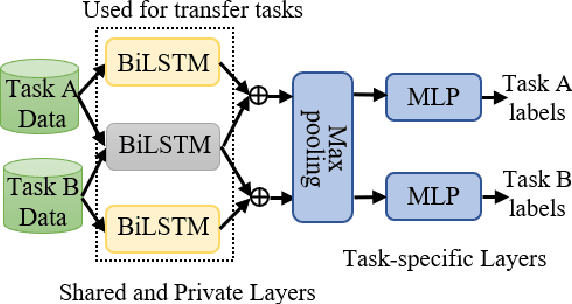

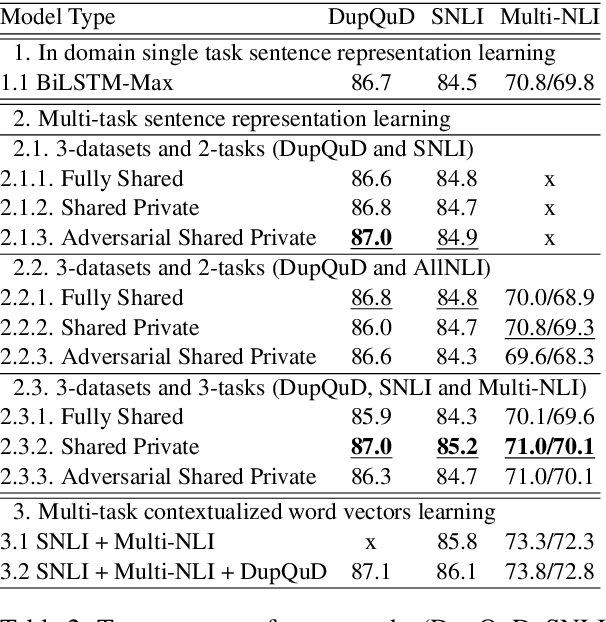
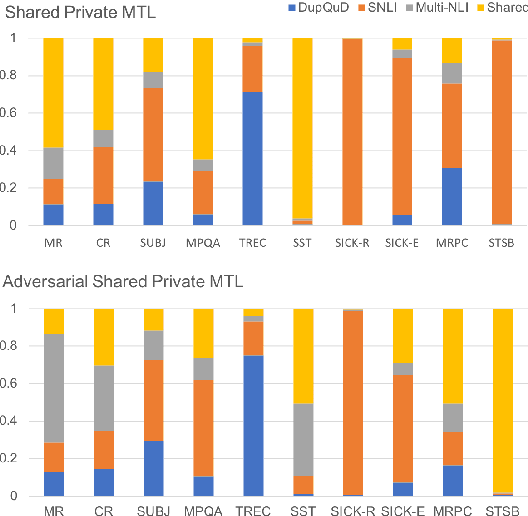
Learning distributed sentence representations is one of the key challenges in natural language processing. Previous work demonstrated that a recurrent neural network (RNNs) based sentence encoder trained on a large collection of annotated natural language inference data, is efficient in the transfer learning to facilitate other related tasks. In this paper, we show that joint learning of multiple tasks results in better generalizable sentence representations by conducting extensive experiments and analysis comparing the multi-task and single-task learned sentence encoders. The quantitative analysis using auxiliary tasks show that multi-task learning helps to embed better semantic information in the sentence representations compared to single-task learning. In addition, we compare multi-task sentence encoders with contextualized word representations and show that combining both of them can further boost the performance of transfer learning.