 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Dependent Coresets for Compressing Neural Networks with Applications to Generalization Bounds
Paper and Code
Sep 05, 2018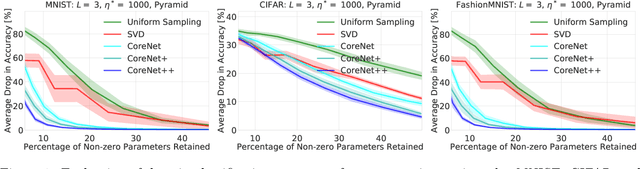
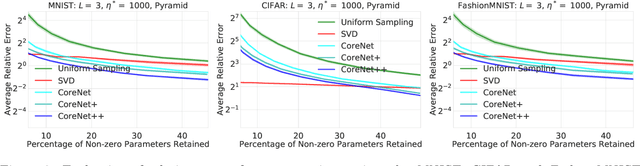
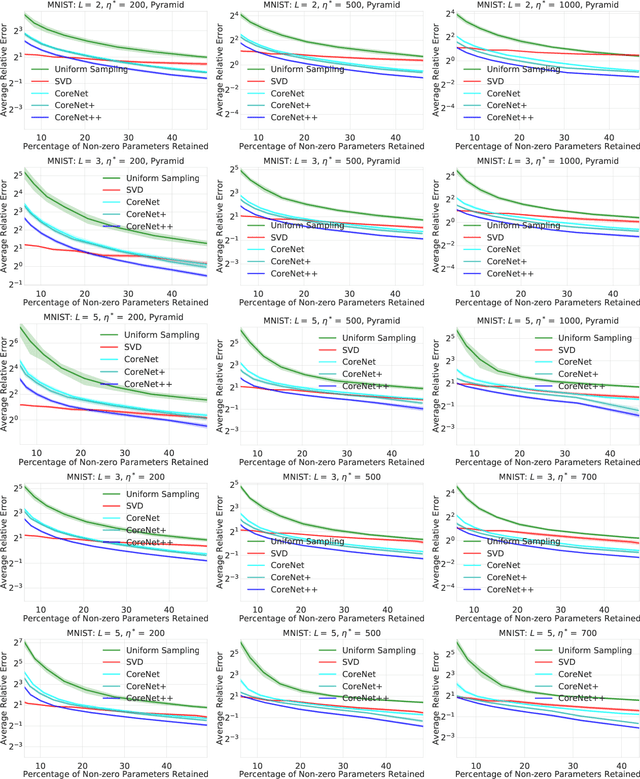
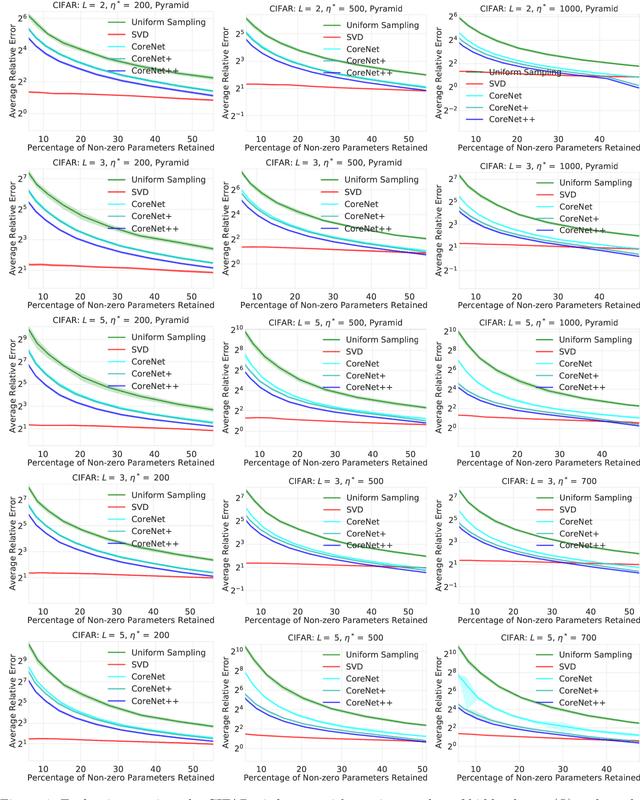
We present an efficient coresets-based neural network compression algorithm that provably sparsifies the parameters of a trained fully-connected neural network in a manner that approximately preserves the network's output. Our approach is based on an importance sampling scheme that judiciously defines a sampling distribution over the neural network parameters, and as a result, retains parameters of high importance while discarding redundant ones. We leverage a novel, empirical notion of sensitivity and extend traditional coreset constructions to the application of compressing parameters. Our theoretical analysis establishes guarantees on the size and accuracy of the resulting compressed neural network and gives rise to new generalization bounds that may provide novel insights on the generalization properties of neural networks. We demonstrate the practical effectiveness of our algorithm on a variety of neural network configurations and real-world data sets.