 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecise Temporal Action Localization by Evolving Temporal Proposals
Paper and Code
Apr 13, 2018
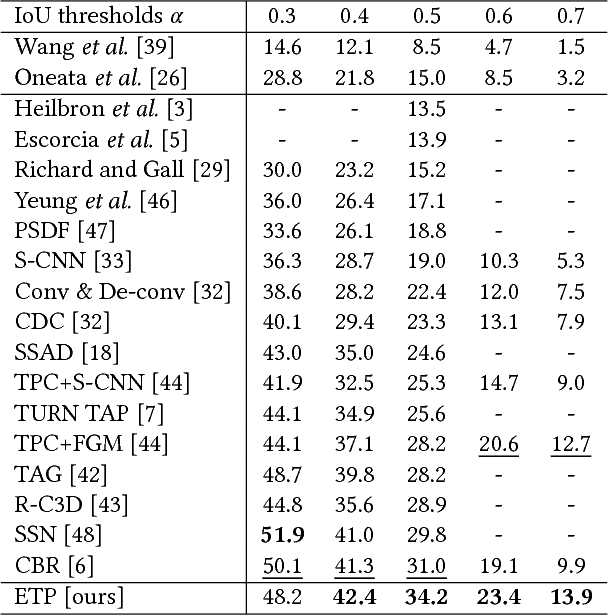
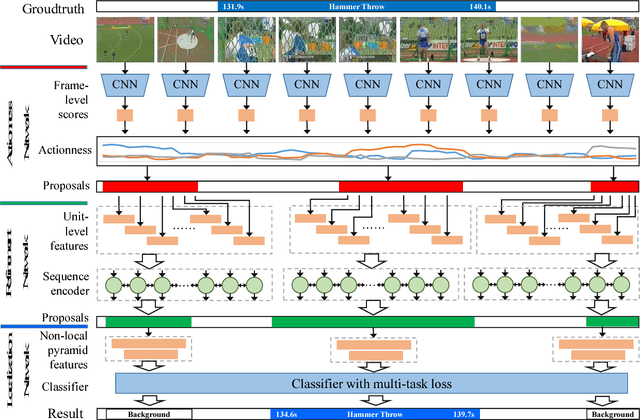
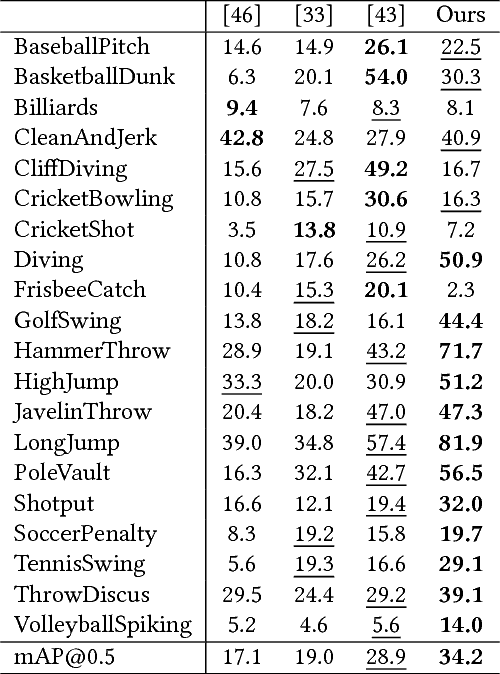
Locating actions in long untrimmed videos has been a challenging problem in video content analysis. The performances of existing action localization approaches remain unsatisfactory in precisely determining the beginning and the end of an action. Imitating the human perception procedure with observations and refinements, we propose a novel three-phase action localization framework. Our framework is embedded with an Actionness Network to generate initial proposals through frame-wise similarity grouping, and then a Refinement Network to conduct boundary adjustment on these proposals. Finally, the refined proposals are sent to a Localization Network for further fine-grained location regression. The whole process can be deemed as multi-stage refinement using a novel non-local pyramid feature under various temporal granularities. We evaluate our framework on THUMOS14 benchmark and obtain a significant improvement over the state-of-the-arts approaches. Specifically, the performance gain is remarkable under precise localization with high IoU thresholds. Our proposed framework achieves mAP@IoU=0.5 of 34.2%.