 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-scale Attribute Dataset for Zero-shot Learning
Paper and Code

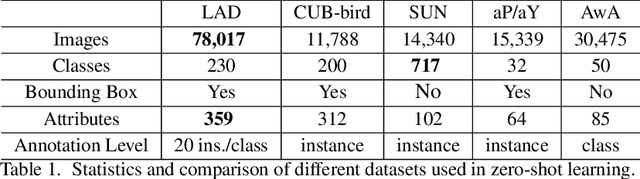
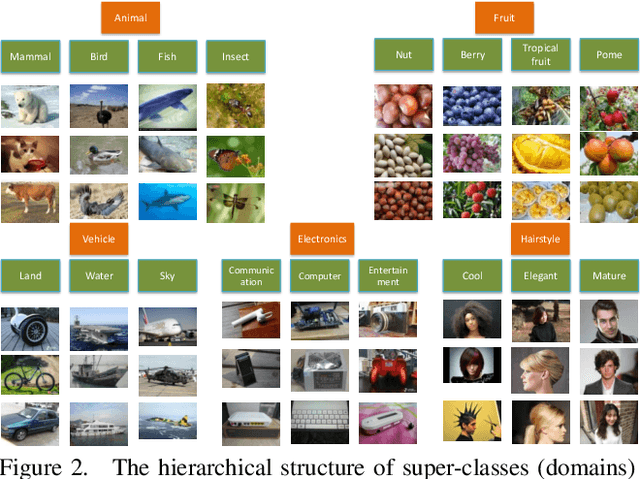
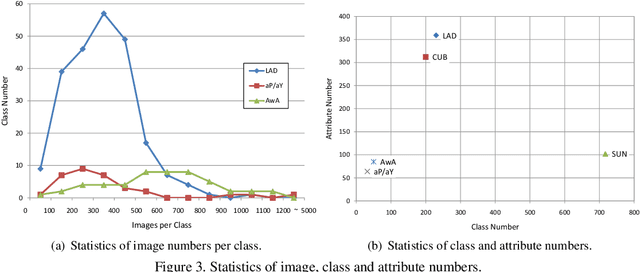
Zero-Shot Learning (ZSL) has attracted huge research attention over the past few years; it aims to learn the new concepts that have never been seen before. In classical ZSL algorithms, attributes are introduced as the intermediate semantic representation to realize the knowledge transfer from seen classes to unseen classes. Previous ZSL algorithms are tested on several benchmark datasets annotated with attributes. However, these datasets are defective in terms of the image distribution and attribute diversity. In addition, we argue that the "co-occurrence bias problem" of existing datasets, which is caused by the biased co-occurrence of objects, significantly hinders models from correctly learning the concept. To overcome these problems, we propose a Large-scale Attribute Dataset (LAD). Our dataset has 78,017 images of 5 super-classes, 230 classes. The image number of LAD is larger than the sum of the four most popular attribute datasets. 359 attributes of visual, semantic and subjective properties are defined and annotated in instance-level. We analyze our dataset by conducting both supervised learning and zero-shot learning tasks. Seven state-of-the-art ZSL algorithms are tested on this new dataset. The experimental results reveal the challenge of implementing zero-shot learning on our dataset.