 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Binary Pattern Networks
Paper and Code
Mar 22, 2018
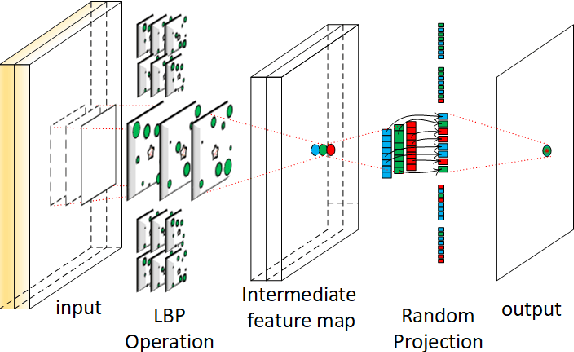
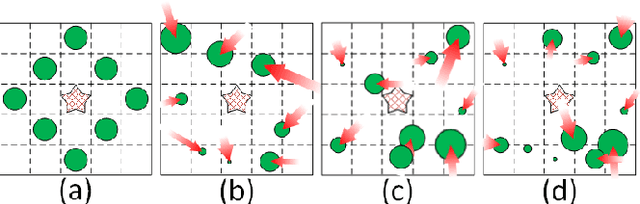
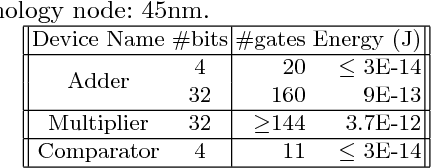
Memory and computation efficient deep learning architec- tures are crucial to continued proliferation of machine learning capabili- ties to new platforms and systems. Binarization of operations in convo- lutional neural networks has shown promising results in reducing model size and computing efficiency. In this paper, we tackle the problem us- ing a strategy different from the existing literature by proposing local binary pattern networks or LBPNet, that is able to learn and perform binary operations in an end-to-end fashion. LBPNet1 uses local binary comparisons and random projection in place of conventional convolu- tion (or approximation of convolution) operations. These operations can be implemented efficiently on different platforms including direct hard- ware implementation. We applied LBPNet and its variants on standard benchmarks. The results are promising across benchmarks while provid- ing an important means to improve memory and speed efficiency that is particularly suited for small footprint devices and hardware accelerators.