 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neurorobotic Experiment for Crossmodal Conflict Resolution in Complex Environments
Paper and Code
Sep 24, 2018
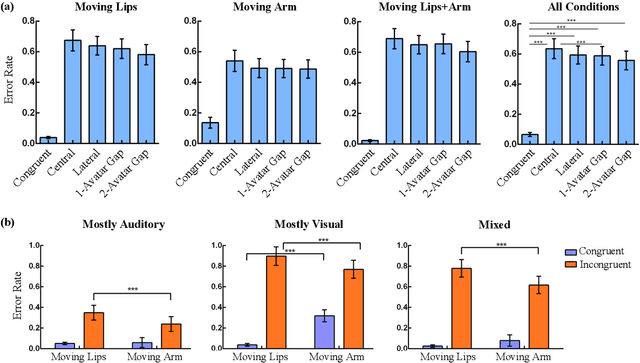
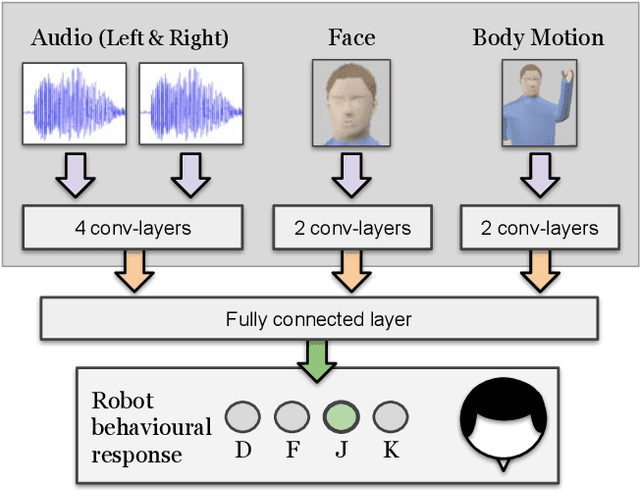
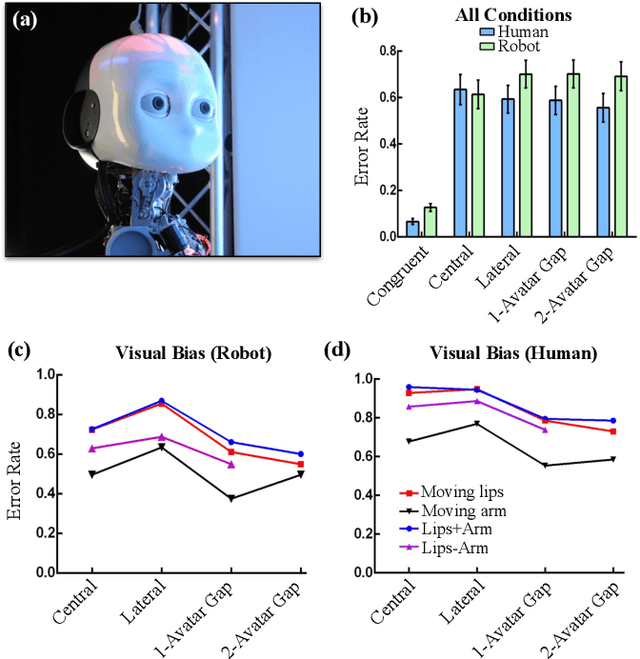
Crossmodal conflict resolution is crucial for robot sensorimotor coupling through the interaction with the environment, yielding swift and robust behaviour also in noisy conditions. In this paper, we propose a neurorobotic experiment in which an iCub robot exhibits human-like responses in a complex crossmodal environment. To better understand how humans deal with multisensory conflicts, we conducted a behavioural study exposing 33 subjects to congruent and incongruent dynamic audio-visual cues. In contrast to previous studies using simplified stimuli, we designed a scenario with four animated avatars and observed that the magnitude and extension of the visual bias are related to the semantics embedded in the scene, i.e., visual cues that are congruent with environmental statistics (moving lips and vocalization) induce the strongest bias. We implement a deep learning model that processes stereophonic sound, facial features, and body motion to trigger a discrete behavioural response. After training the model, we exposed the iCub to the same experimental conditions as the human subjects, showing that the robot can replicate similar responses in real time. Our interdisciplinary work provides important insights into how crossmodal conflict resolution can be modelled in robots and introduces future research directions for the efficient combination of sensory observations with internally generated knowledge and expectations.