 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD2KE: From Distance to Kernel and Embedding
Paper and Code
May 25, 2018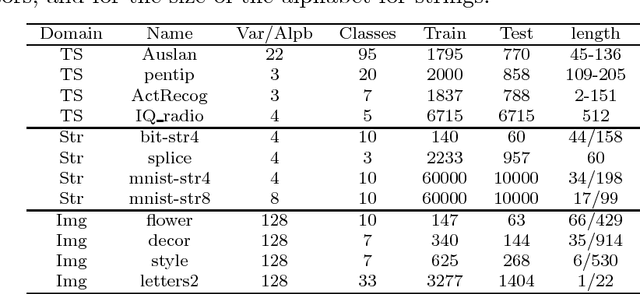



For many machine learning problem settings, particularly with structured inputs such as sequences or sets of objects, a distance measure between inputs can be specified more naturally than a feature representation. However, most standard machine models are designed for inputs with a vector feature representation. In this work, we consider the estimation of a function $f:\mathcal{X} \rightarrow \R$ based solely on a dissimilarity measure $d:\mathcal{X}\times\mathcal{X} \rightarrow \R$ between inputs. In particular, we propose a general framework to derive a family of \emph{positive definite kernels} from a given dissimilarity measure, which subsumes the widely-used \emph{representative-set method} as a special case, and relates to the well-known \emph{distance substitution kernel} in a limiting case. We show that functions in the corresponding Reproducing Kernel Hilbert Space (RKHS) are Lipschitz-continuous w.r.t. the given distance metric. We provide a tractable algorithm to estimate a function from this RKHS, and show that it enjoys better generalizability than Nearest-Neighbor estimates. Our approach draws from the literature of Random Features, but instead of deriving feature maps from an existing kernel, we construct novel kernels from a random feature map, that we specify given the distance measure. We conduct classification experiments with such disparate domains as strings, time series, and sets of vectors, where our proposed framework compares favorably to existing distance-based learning methods such as $k$-nearest-neighbors, distance-substitution kernels, pseudo-Euclidean embedding, and the representative-set method.