 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Gradients for General Contextual Bandits
Paper and Code
May 22, 2018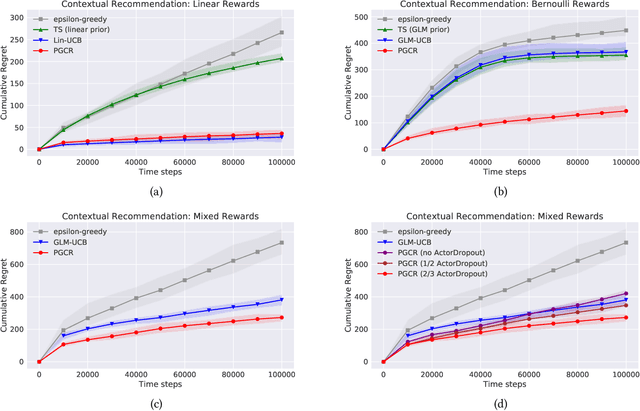
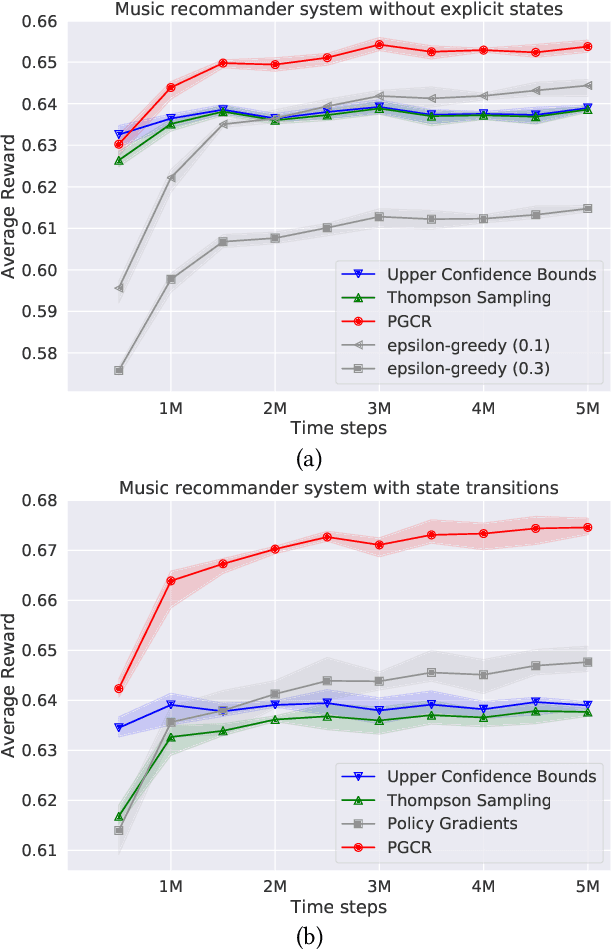
Contextual bandits algorithms have been successfully deployed to various industrial applications for the trade-off between exploration and exploitation and the state-of-art performance on minimizing online costs. However, the applicability is limited by the over-simplified assumptions on the problem, such as assuming the rewards linearly depend on the contexts, or assuming a static environment where the states are not affected by previous actions. In this work, we put forward an alternative method for general contextual bandits using actor-critic neural networks to directly optimize in the policy space, coined policy gradient for contextual bandits (PGCB). It optimizes over a class of policies in which the marginal probability of choosing an arm (in expectation of other arms) has a simple closed form so that the objective is differentiable. In particular, the gradient of this class of policies is in a succinct form. Moreover, we propose two useful heuristic techniques called Time-Dependent Greed and Actor-Dropout. The former ensures PGCB to be empirically greedy in the limit, while the later balances a trade-off between exploration and exploitation by using the actor-network with dropout as a Bayesian approximation. PGCB can solve contextual bandits in the standard case as well as the Markov Decision Process generalization where there is a state that decides the distribution of contexts of arms and affects the immediate reward when choosing an arm, therefore can be applied to a wide range of realistic settings such as personalized recommender systems and natural language generations. We evaluate PGCB on toy datasets as well as a music recommender dataset. Experiments show that PGCB has fast convergence and low regret and outperforms both classic contextual-bandits methods and vanilla policy gradient methods.