 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVehicle Pose and Shape Estimation through Multiple Monocular Vision
Paper and Code
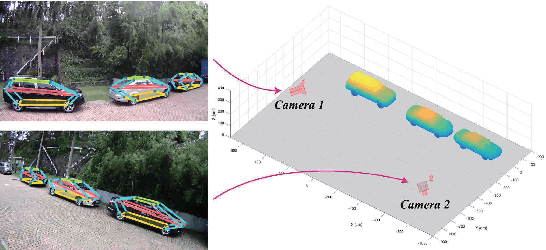
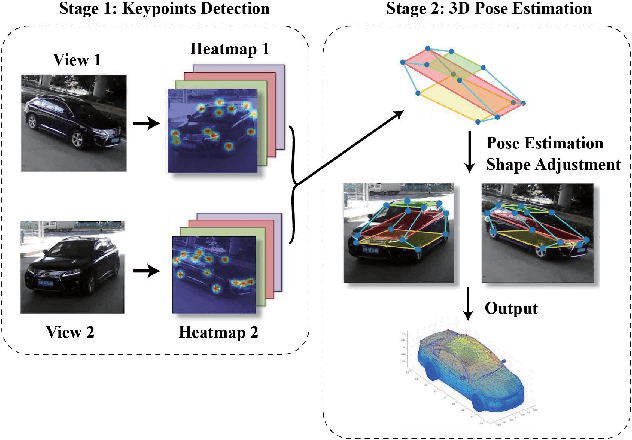
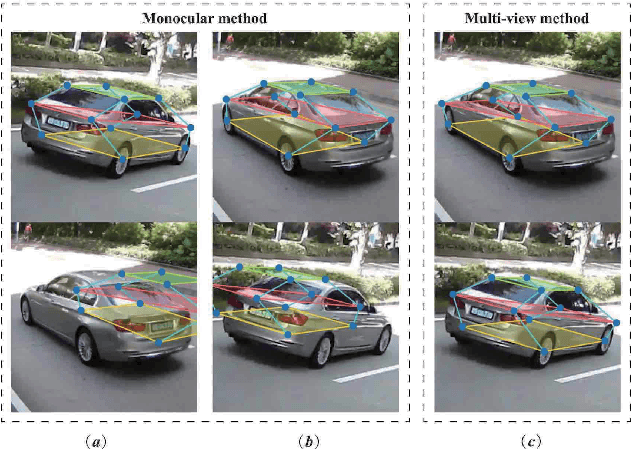
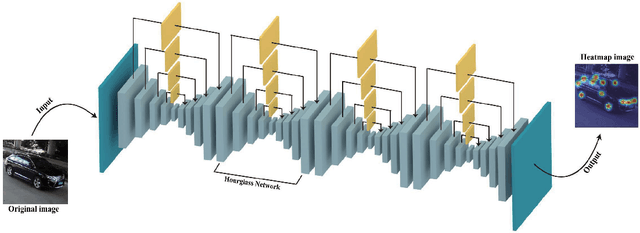
In this paper, we present an accurate approach to estimate vehicles' pose and shape from off-board multiview images. The images are taken by monocular cameras and have small overlaps. We utilize state-of-the-art convolutional neural networks (CNNs) to extract vehicles' semantic keypoints and introduce a Cross Projection Optimization (CPO) method to estimate the 3D pose. During the iterative CPO process, an adaptive shape adjustment method named Hierarchical Wireframe Constraint (HWC) is implemented to estimate the shape. Our approach is evaluated under both simulated and real-world scenes for performance verification. It's shown that our algorithm outperforms other existing monocular and stereo methods for vehicles' pose and shape estimation. This approach provides a new and robust solution for off-board visual vehicle localization and tracking, which can be applied to massive surveillance camera networks for intelligent transportation.