 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Learning for Chinese NER from Crowd Annotations
Paper and Code
Jan 16, 2018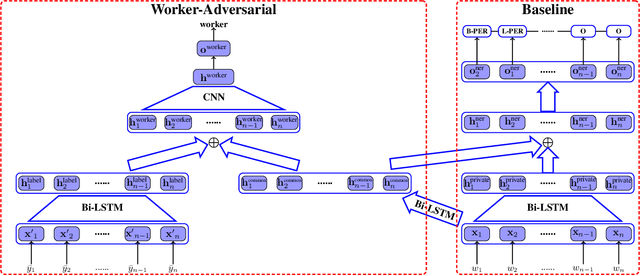
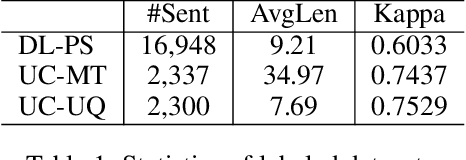
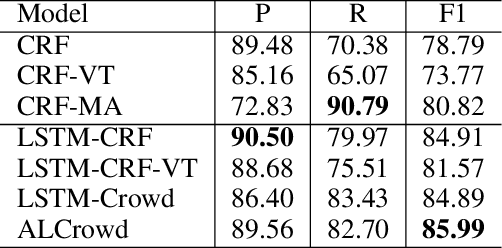
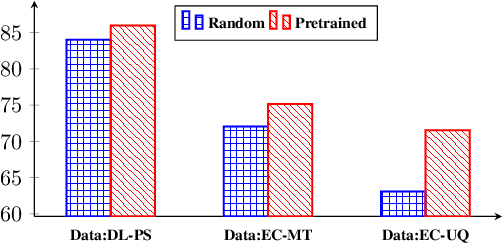
To quickly obtain new labeled data, we can choose crowdsourcing as an alternative way at lower cost in a short time. But as an exchange, crowd annotations from non-experts may be of lower quality than those from experts. In this paper, we propose an approach to performing crowd annotation learning for Chinese Named Entity Recognition (NER) to make full use of the noisy sequence labels from multiple annotators. Inspired by adversarial learning, our approach uses a common Bi-LSTM and a private Bi-LSTM for representing annotator-generic and -specific information. The annotator-generic information is the common knowledge for entities easily mastered by the crowd. Finally, we build our Chinese NE tagger based on the LSTM-CRF model. In our experiments, we create two data sets for Chinese NER tasks from two domains. The experimental results show that our system achieves better scores than strong baseline systems.