 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSkeleton: Skeleton Map for 3D Human Pose Regression
Paper and Code
Nov 29, 2017
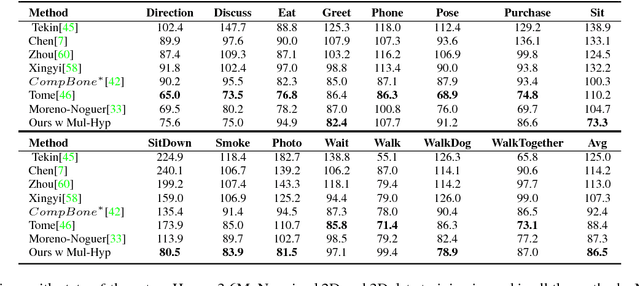
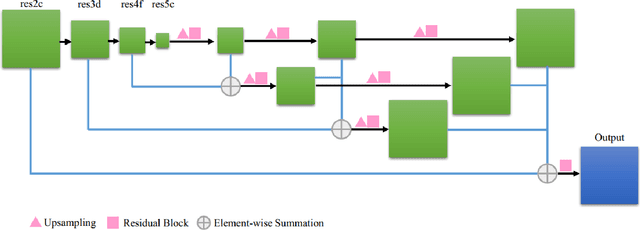
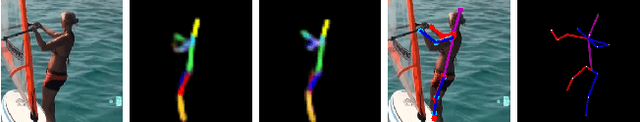
Despite recent success on 2D human pose estimation, 3D human pose estimation still remains an open problem. A key challenge is the ill-posed depth ambiguity nature. This paper presents a novel intermediate feature representation named skeleton map for regression. It distills structural context from irrelavant properties of RGB image e.g. illumination and texture. It is simple, clean and can be easily generated via deconvolution network. For the first time, we show that training regression network from skeleton map alone is capable of meeting the performance of state-of-theart 3D human pose estimation works. We further exploit the power of multiple 3D hypothesis generation to obtain reasonbale 3D pose in consistent with 2D pose detection. The effectiveness of our approach is validated on challenging in-the-wild dataset MPII and indoor dataset Human3.6M.