 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdsourcing Question-Answer Meaning Representations
Paper and Code

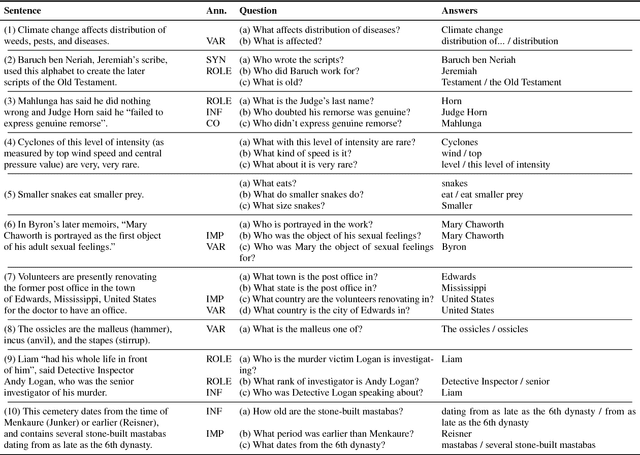
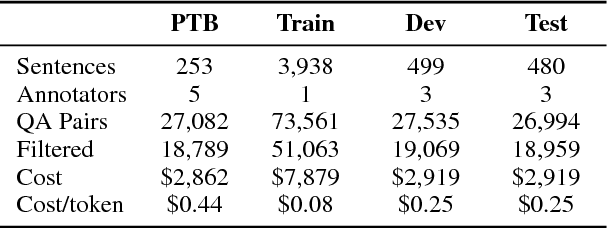
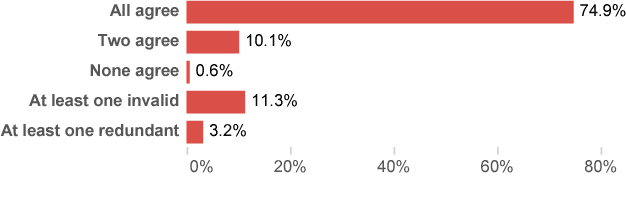
We introduce Question-Answer Meaning Representations (QAMRs), which represent the predicate-argument structure of a sentence as a set of question-answer pairs. We also develop a crowdsourcing scheme to show that QAMRs can be labeled with very little training, and gather a dataset with over 5,000 sentences and 100,000 questions. A detailed qualitative analysis demonstrates that the crowd-generated question-answer pairs cover the vast majority of predicate-argument relationships in existing datasets (including PropBank, NomBank, QA-SRL, and AMR) along with many previously under-resourced ones, including implicit arguments and relations. The QAMR data and annotation code is made publicly available to enable future work on how best to model these complex phenomena.