 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigation without localisation: reliable teach and repeat based on the convergence theorem
Paper and Code
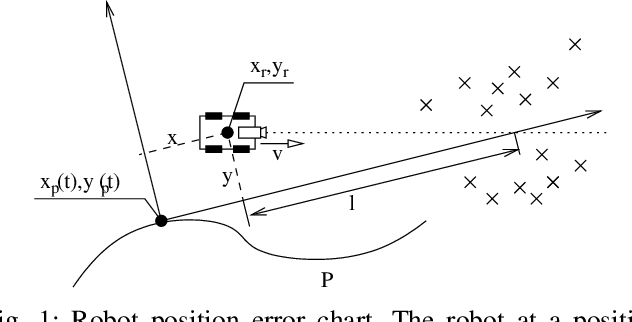
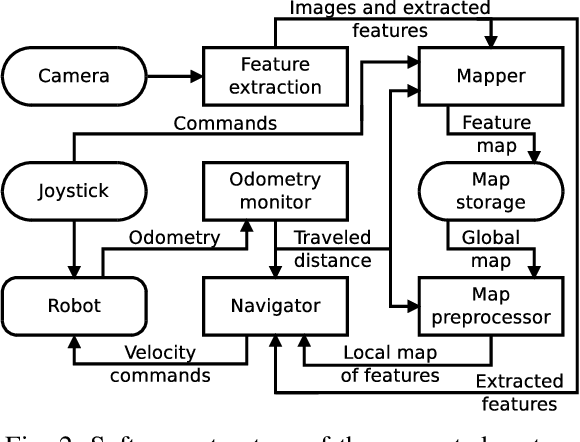

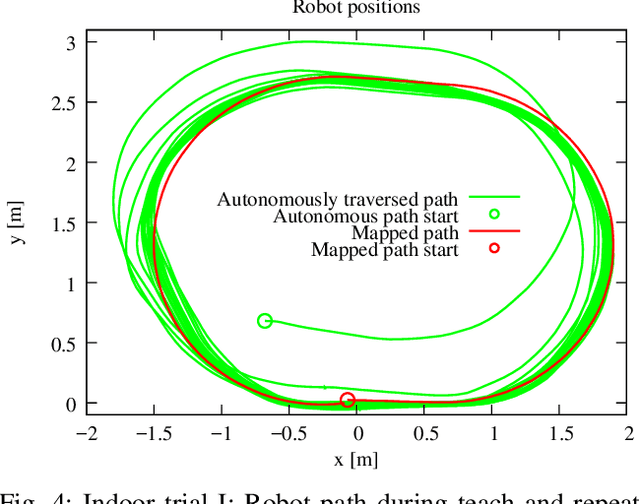
We present a novel concept for teach-and-repeat visual navigation. The proposed concept is based on a mathematical model, which indicates that in teach-and-repeat navigation scenarios, mobile robots do not need to perform explicit localisation. Rather than that, a mobile robot which repeats a previously taught path can simply `replay' the learned velocities, while using its camera information only to correct its heading relative to the intended path. To support our claim, we establish a position error model of a robot, which traverses a taught path by only correcting its heading. Then, we outline a mathematical proof which shows that this position error does not diverge over time. Based on the insights from the model, we present a simple monocular teach-and-repeat navigation method. The method is computationally efficient, it does not require camera calibration, and it can learn and autonomously traverse arbitrarily-shaped paths. In a series of experiments, we demonstrate that the method can reliably guide mobile robots in realistic indoor and outdoor conditions, and can cope with imperfect odometry, landmark deficiency, illumination variations and naturally-occurring environment changes. Furthermore, we provide the navigation system and the datasets gathered at http://www.github.com/gestom/stroll_bearnav.