 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Sparsification for Communication-Efficient Distributed Optimization
Paper and Code
Oct 26, 2017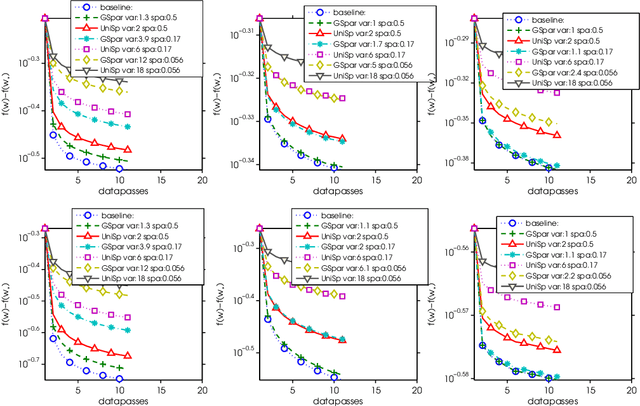
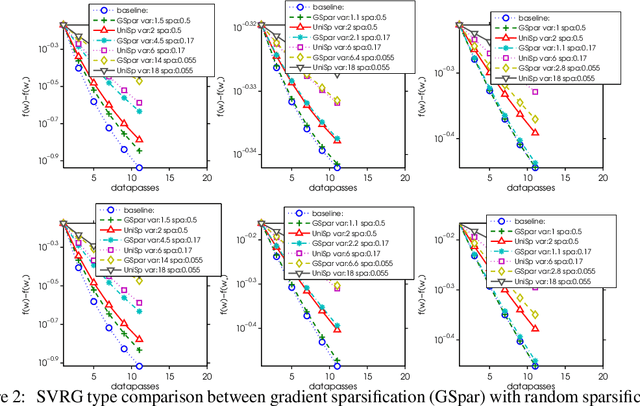
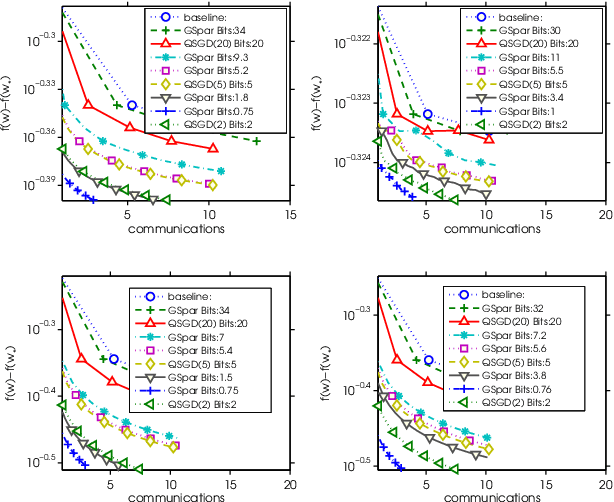
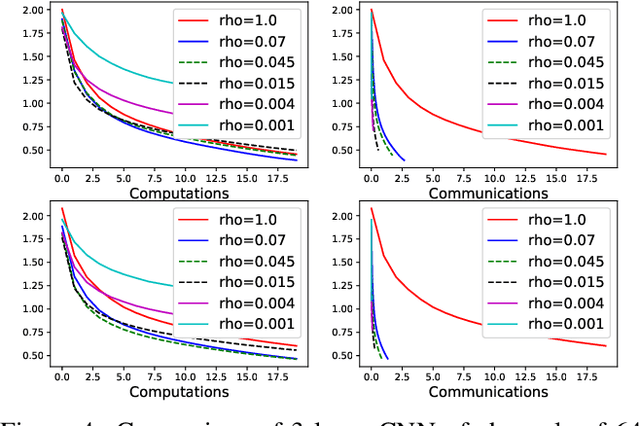
Modern large scale machine learning applications require stochastic optimization algorithms to be implemented on distributed computational architectures. A key bottleneck is the communication overhead for exchanging information such as stochastic gradients among different workers. In this paper, to reduce the communication cost we propose a convex optimization formulation to minimize the coding length of stochastic gradients. To solve the optimal sparsification efficiently, several simple and fast algorithms are proposed for approximate solution, with theoretical guaranteed for sparseness. Experiments on $\ell_2$ regularized logistic regression, support vector machines, and convolutional neural networks validate our sparsification approaches.