 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSE3-Pose-Nets: Structured Deep Dynamics Models for Visuomotor Planning and Control
Paper and Code
Oct 02, 2017
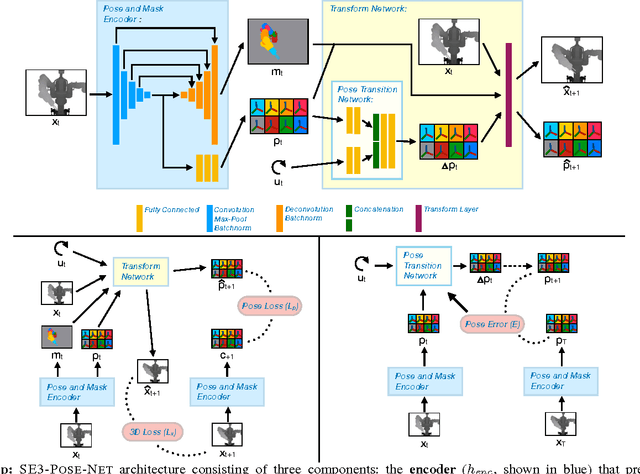
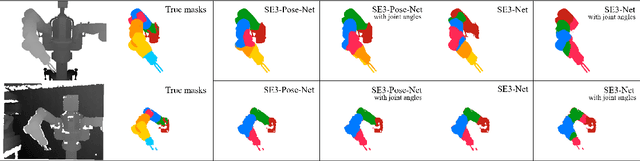
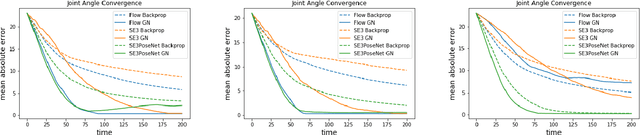
In this work, we present an approach to deep visuomotor control using structured deep dynamics models. Our deep dynamics model, a variant of SE3-Nets, learns a low-dimensional pose embedding for visuomotor control via an encoder-decoder structure. Unlike prior work, our dynamics model is structured: given an input scene, our network explicitly learns to segment salient parts and predict their pose-embedding along with their motion modeled as a change in the pose space due to the applied actions. We train our model using a pair of point clouds separated by an action and show that given supervision only in the form of point-wise data associations between the frames our network is able to learn a meaningful segmentation of the scene along with consistent poses. We further show that our model can be used for closed-loop control directly in the learned low-dimensional pose space, where the actions are computed by minimizing error in the pose space using gradient-based methods, similar to traditional model-based control. We present results on controlling a Baxter robot from raw depth data in simulation and in the real world and compare against two baseline deep networks. Our method runs in real-time, achieves good prediction of scene dynamics and outperforms the baseline methods on multiple control runs. Video results can be found at: https://rse-lab.cs.washington.edu/se3-structured-deep-ctrl/