 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImageNet Training in Minutes
Paper and Code
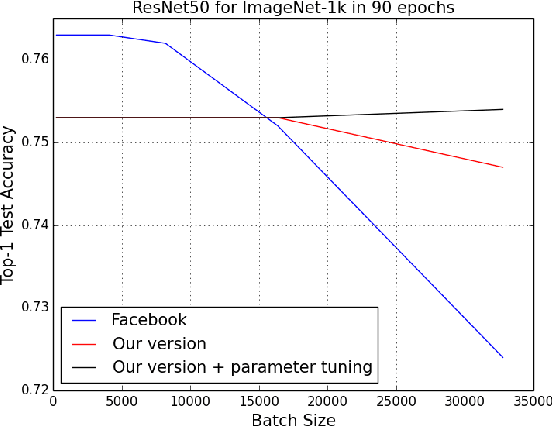


Finishing 90-epoch ImageNet-1k training with ResNet-50 on a NVIDIA M40 GPU takes 14 days. This training requires 10^18 single precision operations in total. On the other hand, the world's current fastest supercomputer can finish 2 * 10^17 single precision operations per second (Dongarra et al 2017, https://www.top500.org/lists/2017/06/). If we can make full use of the supercomputer for DNN training, we should be able to finish the 90-epoch ResNet-50 training in one minute. However, the current bottleneck for fast DNN training is in the algorithm level. Specifically, the current batch size (e.g. 512) is too small to make efficient use of many processors. For large-scale DNN training, we focus on using large-batch data-parallelism synchronous SGD without losing accuracy in the fixed epochs. The LARS algorithm (You, Gitman, Ginsburg, 2017, arXiv:1708.03888) enables us to scale the batch size to extremely large case (e.g. 32K). We finish the 100-epoch ImageNet training with AlexNet in 11 minutes on 1024 CPUs. About three times faster than Facebook's result (Goyal et al 2017, arXiv:1706.02677), we finish the 90-epoch ImageNet training with ResNet-50 in 20 minutes on 2048 KNLs without losing accuracy. State-of-the-art ImageNet training speed with ResNet-50 is 74.9% top-1 test accuracy in 15 minutes. We got 74.9% top-1 test accuracy in 64 epochs, which only needs 14 minutes. Furthermore, when we increase the batch size to above 16K, our accuracy is much higher than Facebook's on corresponding batch sizes. Our source code is available upon request.