 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocusing Attention: Towards Accurate Text Recognition in Natural Images
Paper and Code
Oct 17, 2017
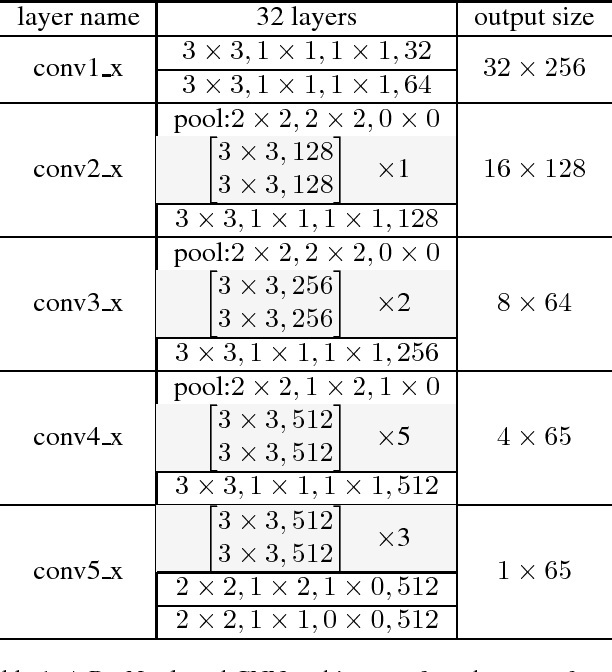
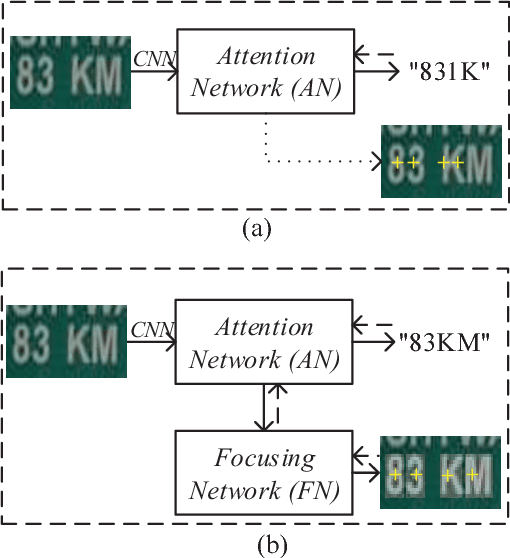
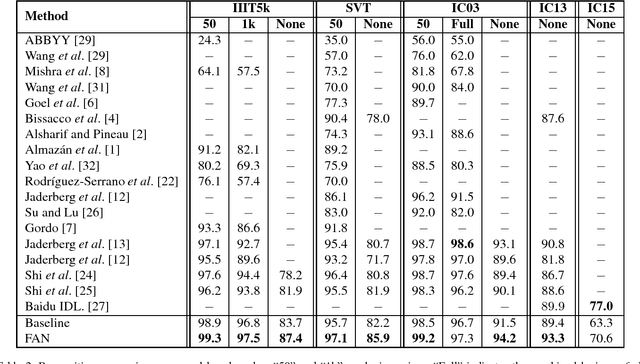
Scene text recognition has been a hot research topic in computer vision due to its various applications. The state of the art is the attention-based encoder-decoder framework that learns the mapping between input images and output sequences in a purely data-driven way. However, we observe that existing attention-based methods perform poorly on complicated and/or low-quality images. One major reason is that existing methods cannot get accurate alignments between feature areas and targets for such images. We call this phenomenon "attention drift". To tackle this problem, in this paper we propose the FAN (the abbreviation of Focusing Attention Network) method that employs a focusing attention mechanism to automatically draw back the drifted attention. FAN consists of two major components: an attention network (AN) that is responsible for recognizing character targets as in the existing methods, and a focusing network (FN) that is responsible for adjusting attention by evaluating whether AN pays attention properly on the target areas in the images. Furthermore, different from the existing methods, we adopt a ResNet-based network to enrich deep representations of scene text images. Extensive experiments on various benchmarks, including the IIIT5k, SVT and ICDAR datasets, show that the FAN method substantially outperforms the existing methods.